在处理矩阵的并行分解时,我熟悉块分配,其中我们有(例如)4个进程,每个进程都有自己的矩阵子区域:
他们硬编码了
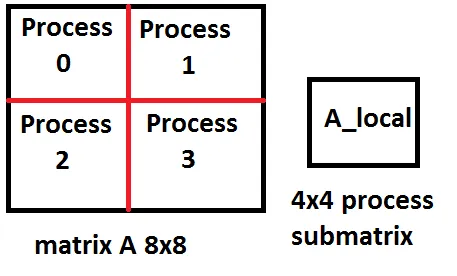
procrows)设置为2,列中的进程数(proccols)也设置为2,如果原始矩阵大小为 N x M,则子矩阵A_local的大小为N/2 x M/2。我正在阅读这个 example,它使用“块循环”分配,在这部分中:/* Begin Cblas context */
/* We assume that we have 4 processes and place them in a 2-by-2 grid */
int ctxt, myid, myrow, mycol, numproc;
int procrows = 2, proccols = 2;
Cblacs_pinfo(&myid, &numproc);
Cblacs_get(0, 0, &ctxt);
Cblacs_gridinit(&ctxt, "Row-major", procrows, proccols);
他们硬编码了
procrows 和 proccols,但对于一个被读入的矩阵,有一个标题:我不理解这个,难道Nb 和 Mb 将是矩阵块的行数和列数
Nb 和 Mb 不完全由 N、M、procrows 和 proccols 确定吗?
编辑
从运行示例中,我可以看到进程0上的子矩阵具有矩阵左上角的所有元素,就像我上面的图片一样,这与Jonathan的答案相矛盾。然而,它在ScaLAPACK的Cholesky中正常工作。
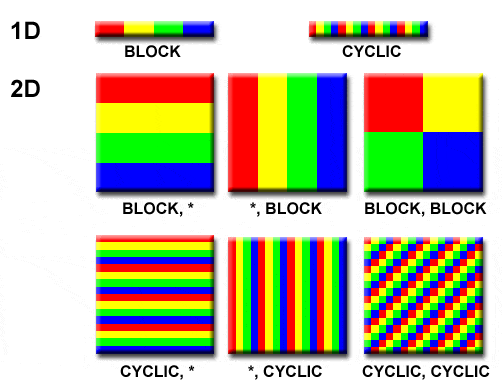
Nb = Mb = 2。感谢您的评论,但至少在这个时候对我来说没有意义。 :/ - gsamarasprocrows = Nb吗?另外,您会回答吗? - gsamaras