我正开始学习 Pandas,并且正在尝试找到实现某些任务的最 Pythonic(或“Panda-thonic”)方法。
假设我们有一个包含列 A、B 和 C 的 DataFrame。
列 A 包含布尔值:每行的 A 值都是 true 或 false。
列 B 具有一些重要值,我们想要绘制这些值。
我们想要发现的是,对于将 A 设置为 false 的行和对于 A 为 true 的行,B 值之间的微妙差别。
换句话说,如何按列 A 的值(true 或 false)进行分组,然后在同一图表上绘制两个组的列 B 值?这两个数据集应该以不同的颜色着色,以便区分数据点。
接下来,让我们为这个程序添加另一个特性:在绘图之前,我们要计算每行的另一个值并将其存储在列 D 中。这个值是在记录前五分钟内存储在列 B 中的所有数据的平均值,但我们只包括存储在 A 中相同布尔值的行。
换句话说,如果我有一个行,其中 A=True 并且 time=t,则我希望为每个时间点 t 计算一个列 D 的值,该值是从时间 t-5 到 t 中存储了相同布尔值 A=True 的所有记录的 B 值的平均值。
在这种情况下,我们如何按 A 的值执行 groupby,然后将此计算应用于每个单独的组,并最终绘制两个组的 D 值?
假设我们有一个包含列 A、B 和 C 的 DataFrame。
列 A 包含布尔值:每行的 A 值都是 true 或 false。
列 B 具有一些重要值,我们想要绘制这些值。
我们想要发现的是,对于将 A 设置为 false 的行和对于 A 为 true 的行,B 值之间的微妙差别。
换句话说,如何按列 A 的值(true 或 false)进行分组,然后在同一图表上绘制两个组的列 B 值?这两个数据集应该以不同的颜色着色,以便区分数据点。
接下来,让我们为这个程序添加另一个特性:在绘图之前,我们要计算每行的另一个值并将其存储在列 D 中。这个值是在记录前五分钟内存储在列 B 中的所有数据的平均值,但我们只包括存储在 A 中相同布尔值的行。
换句话说,如果我有一个行,其中 A=True 并且 time=t,则我希望为每个时间点 t 计算一个列 D 的值,该值是从时间 t-5 到 t 中存储了相同布尔值 A=True 的所有记录的 B 值的平均值。
在这种情况下,我们如何按 A 的值执行 groupby,然后将此计算应用于每个单独的组,并最终绘制两个组的 D 值?
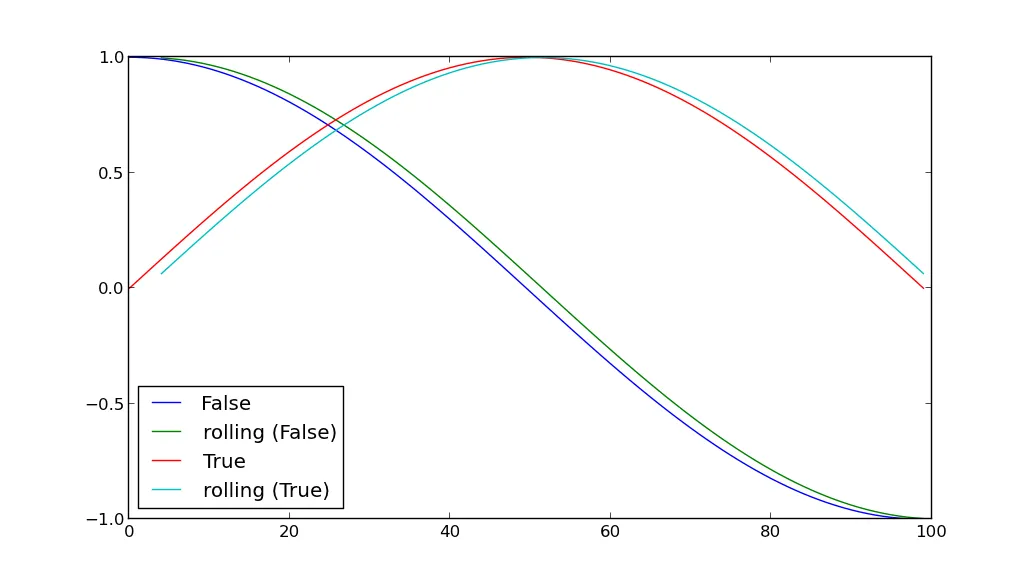
grouped = df.groupby('A'),然后用for循环绘制图表:for g, d in grouped: plot(d['B'], color=g)。第二个问题也差不多,可以使用pandas的rolling_mean来创建新列D。 - herrfz