如果我理解您的意思正确,您想将一个新的未知数据点分配给类1或类2,而这两个类别各自具有描述符(在本例中为均值向量和协方差矩阵),这些描述符是通过gmdistribution.fit找到的。
在看到这个新数据点x时,您应该问自己什么是p(modeldata1 | x)和p(modeldata2 | x),并且无论哪一个最大,都应该将x分配给它。
那么如何找到这些值呢?您只需要应用贝叶斯规则,并选择以下哪个是最大的:
p(modeldata1 | x) = p(x|modeldata1)p(modeldata1)/p(x)
p(modeldata1 | x) = p(x|modeldata2)p(modeldata2)/p(x)
在这里,您不需要计算p(x),因为它在每个方程中都相同。
因此,现在您可以通过每个类别的训练点数(或使用一些给定信息)来估计先验概率p(modeldata1)和p(modeldata2),然后计算
p(x|modeldata1)=1/((2pi)^d/2 * sqrt(det(Sigma1)))*exp(0.5*(x-mu1)/Sigma1*(x-mu1))
其中d是数据的维度,Sigma是协方差矩阵,mu是均值向量。这就是您所要求的p(data|modeldata1)。(请记得在进行分类时同时使用p(modeldata1)和p(modeldata2))。
我知道这可能有点不清楚,但希望能帮助您朝正确的方向迈进一步。
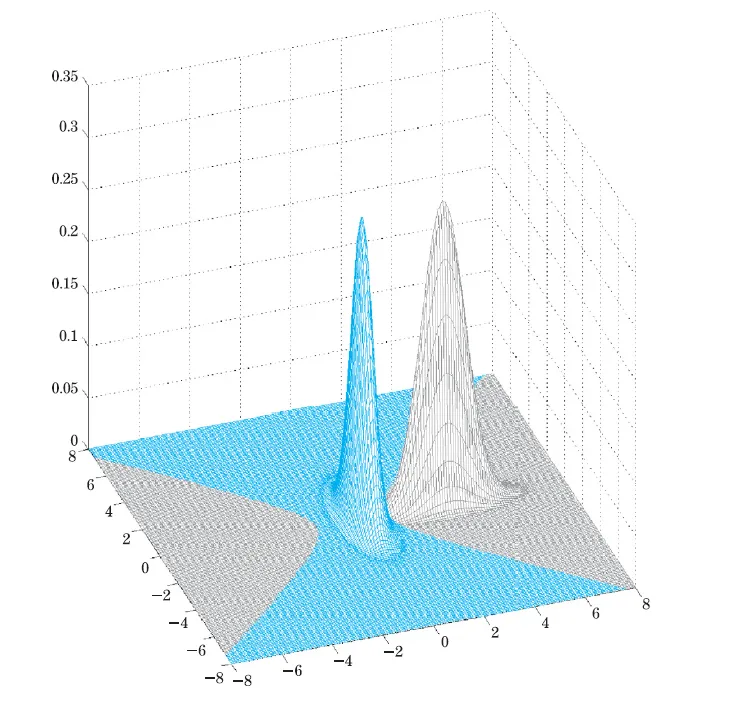
编辑:个人认为像下面这个可视化(来自Theodoridis和Koutroumbas的模式识别)会更好理解。这里有两个高斯混合,具有不同的先验概率和协方差矩阵。蓝色区域是选择一个类别的区域,而灰色区域是选择另一个类别的区域。