我正在尝试尽可能快地解决大量线性方程。为了找出最快的方法,我对NumPy和PyTorch进行了基准测试,分别在CPU和我的GeForce 1080 GPU上运行(使用Numba来优化NumPy)。结果真的让我感到困惑。
这是我在Python 3.8中使用的代码:
最慢的是使用CUDA加速的PyTorch。我验证了PyTorch正在使用我的GPU。
我可以理解,在CPU上,PyTorch比NumPy慢。但我不明白的是为什么在GPU上PyTorch会慢很多。更加令人困惑的是,Numba的njit装饰器会使性能降低几个数量级,直到你不再使用@装饰器语法为止。这可能与我的设置有关。有时我会收到有关Windows页面/交换文件不够大的奇怪消息。如果我在GPU上解决线性方程组的方法完全错误,我希望能得到指导。
这些是结果(运行时间与矩阵边长的关系):
这是结果(运行时间与矩阵边长的关系):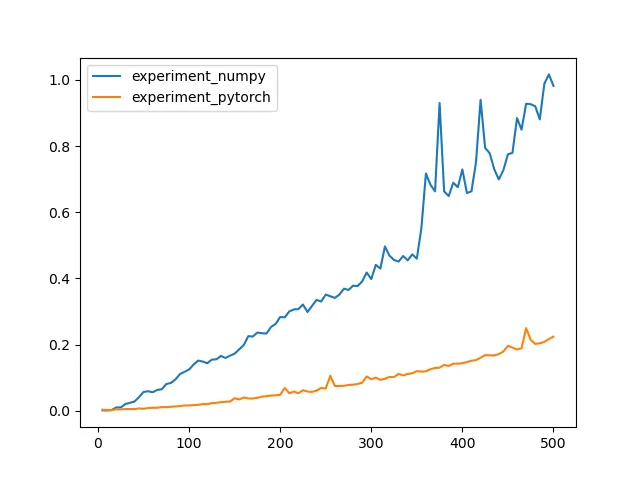 因此,我将继续使用
因此,我将继续使用
如何利用我的GPU更快地解决线性方程?
这是我在Python 3.8中使用的代码:
import timeit
import torch
import numpy
from numba import njit
def solve_numpy_cpu(dim: int = 5):
a = numpy.random.rand(dim, dim)
b = numpy.random.rand(dim)
for _ in range(1000):
numpy.linalg.solve(a, b)
def solve_numpy_njit_a(dim: int = 5):
njit(solve_numpy_cpu, dim=dim)
@njit
def solve_numpy_njit_b(dim: int = 5):
a = numpy.random.rand(dim, dim)
b = numpy.random.rand(dim)
for _ in range(1000):
numpy.linalg.solve(a, b)
def solve_torch_cpu(dim: int = 5):
a = torch.rand(dim, dim)
b = torch.rand(dim, 1)
for _ in range(1000):
torch.solve(b, a)
def solve_torch_gpu(dim: int = 5):
torch.set_default_tensor_type("torch.cuda.FloatTensor")
solve_torch_cpu(dim=dim)
def main():
for f in (solve_numpy_cpu, solve_torch_cpu, solve_torch_gpu, solve_numpy_njit_a, solve_numpy_njit_b):
time = timeit.timeit(f, number=1)
print(f"{f.__name__:<20s}: {time:f}")
if __name__ == "__main__":
main()
这些是结果:
solve_numpy_cpu : 0.007275
solve_torch_cpu : 0.012244
solve_torch_gpu : 5.239126
solve_numpy_njit_a : 0.000158
solve_numpy_njit_b : 1.273660
最慢的是使用CUDA加速的PyTorch。我验证了PyTorch正在使用我的GPU。
import torch
torch.cuda.is_available()
torch.cuda.get_device_name(0)
返回
True
'GeForce GTX 1080'
我可以理解,在CPU上,PyTorch比NumPy慢。但我不明白的是为什么在GPU上PyTorch会慢很多。更加令人困惑的是,Numba的njit装饰器会使性能降低几个数量级,直到你不再使用@装饰器语法为止。这可能与我的设置有关。有时我会收到有关Windows页面/交换文件不够大的奇怪消息。如果我在GPU上解决线性方程组的方法完全错误,我希望能得到指导。
编辑
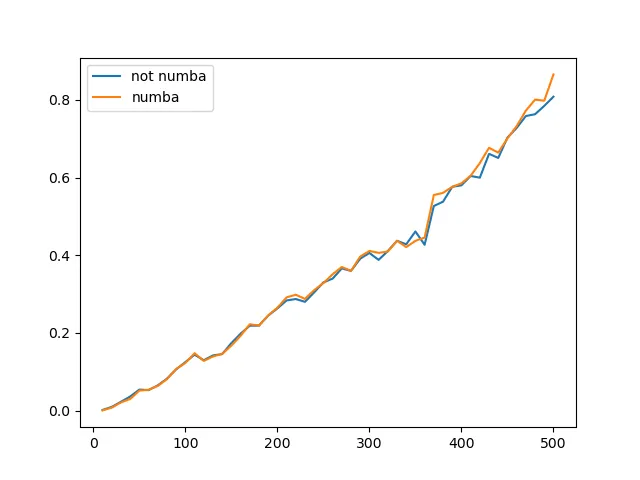
所以,我专注于Numba并稍微改变了我的基准测试。正如@max9111建议的那样,我重写了函数以接收输入并产生输出,因为最终,这就是任何人想要使用它们的原因。现在,我还对Numba加速函数进行了第一次编译运行,以使后续计时更加公平。最后,我检查了性能与矩阵大小之间的关系,并绘制了结果。
TL/DR: 对于500x500以下的矩阵大小,Numba加速对numpy.linalg.solve没有真正的影响。
下面是代码:
import time
from typing import Tuple
import numpy
from matplotlib import pyplot
from numba import jit
@jit(nopython=True)
def solve_numpy_njit(a: numpy.ndarray, b: numpy.ndarray) -> numpy.ndarray:
parameters = numpy.linalg.solve(a, b)
return parameters
def solve_numpy(a: numpy.ndarray, b: numpy.ndarray) -> numpy.ndarray:
parameters = numpy.linalg.solve(a, b)
return parameters
def get_data(dim: int) -> Tuple[numpy.ndarray, numpy.ndarray]:
a = numpy.random.random((dim, dim))
b = numpy.random.random(dim)
return a, b
def main():
a, b = get_data(10)
# compile numba function
p = solve_numpy_njit(a, b)
matrix_size = [(x + 1) * 10 for x in range(50)]
non_accelerated = []
accelerated = []
results = non_accelerated, accelerated
for j, each_matrix_size in enumerate(matrix_size):
for m, f in enumerate((solve_numpy, solve_numpy_njit)):
average_time = -1.
for k in range(5):
time_start = time.time()
for i in range(100):
a, b = get_data(each_matrix_size)
p = f(a, b)
d_t = time.time() - time_start
print(f"{each_matrix_size:d} {f.__name__:<30s}: {d_t:f}")
average_time = (average_time * k + d_t) / (k + 1)
results[m].append(average_time)
pyplot.plot(matrix_size, non_accelerated, label="not numba")
pyplot.plot(matrix_size, accelerated, label="numba")
pyplot.legend()
pyplot.show()
if __name__ == "__main__":
main()
这些是结果(运行时间与矩阵边长的关系):
编辑2
由于Numba在我的情况下并没有带来太大的差异,我回到了对PyTorch进行基准测试。实际上,即使不使用CUDA设备,它似乎比Numpy快大约4倍。
这是我使用的代码:
import time
from typing import Tuple
import numpy
import torch
from matplotlib import pyplot
def solve_numpy(a: numpy.ndarray, b: numpy.ndarray) -> numpy.ndarray:
parameters = numpy.linalg.solve(a, b)
return parameters
def get_data(dim: int) -> Tuple[numpy.ndarray, numpy.ndarray]:
a = numpy.random.random((dim, dim))
b = numpy.random.random(dim)
return a, b
def get_data_torch(dim: int) -> Tuple[torch.tensor, torch.tensor]:
a = torch.rand(dim, dim)
b = torch.rand(dim, 1)
return a, b
def solve_torch(a: torch.tensor, b: torch.tensor) -> torch.tensor:
parameters, _ = torch.solve(b, a)
return parameters
def experiment_numpy(matrix_size: int, repetitions: int = 100):
for i in range(repetitions):
a, b = get_data(matrix_size)
p = solve_numpy(a, b)
def experiment_pytorch(matrix_size: int, repetitions: int = 100):
for i in range(repetitions):
a, b = get_data_torch(matrix_size)
p = solve_torch(a, b)
def main():
matrix_size = [x for x in range(5, 505, 5)]
experiments = experiment_numpy, experiment_pytorch
results = tuple([] for _ in experiments)
for i, each_experiment in enumerate(experiments):
for j, each_matrix_size in enumerate(matrix_size):
time_start = time.time()
each_experiment(each_matrix_size, repetitions=100)
d_t = time.time() - time_start
print(f"{each_matrix_size:d} {each_experiment.__name__:<30s}: {d_t:f}")
results[i].append(d_t)
for each_experiment, each_result in zip(experiments, results):
pyplot.plot(matrix_size, each_result, label=each_experiment.__name__)
pyplot.legend()
pyplot.show()
if __name__ == "__main__":
main()
这是结果(运行时间与矩阵边长的关系):
因此,我将继续使用torch.solve。然而,原始问题仍然存在:如何利用我的GPU更快地解决线性方程?