我想使用Pandas来替换表中特定范围内的所有NaN值为其中位数(median)值。虽然我在处理更大的数据集,但是以下是一个例子:
np.random.seed(0)
rng = pd.date_range('2020-09-24', periods=20, freq='0.2H')
df = pd.DataFrame({ 'Date': rng, 'Val': np.random.randn(len(rng)), 'Dist' :np.random.randn(len(rng)) })
df.Dist[df.Dist<=-0.6] = np.nan
df.Val[df.Val<=-0.5] = np.nan
我希望能够将Val和Dist中的NaN值替换为每小时该列的中位数。我已经在另一个参考表中获取了中位数值:
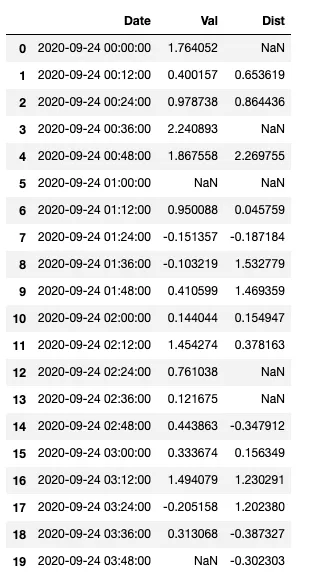
df.set_index('Date', inplace=True)
df = df.assign(Hour = lambda x : x.index.hour)
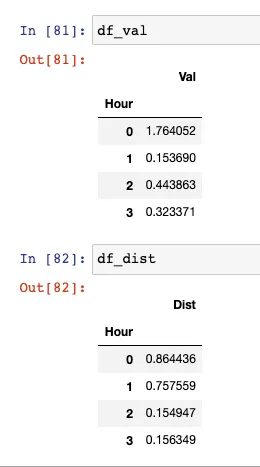
df_val = df[["Val", "Hour"]].groupby("Hour").median()
df_dist = df[["Dist", "Hour"]].groupby("Hour").median()
但现在我已经尝试了下面的所有命令,无论怎样都无法弥补 NaN 值。
df[["Val","Hour"]].mask(df['Val'].isna(), df_val.iloc[df.Hour], inplace=True)
df.where(df['Val'].notna(), other=df_val[df.Hour],axis = 0)
df["Val"] = np.where(df['Val'].notna(), df['Val'], df_val(df.Hour))
df.replace({"Val":{np.nan:df_val[df.Hour]}, "Dist":{np.nan:df_dist[df.Hour]}})
groupby()和transform()之间只有一个间隔? - EddyWD.transform('median')比使用.median更好? - EddyWD.median每组只返回一个值,因此您将获得一个长度等于组数的数据框/系列。transform重新填充组之间的值,因此您将收到与原始数据框具有相同索引的数据框/系列。由于您正在将其分配回原始数据框,因此transform的效果更好。 - Quang Hoang