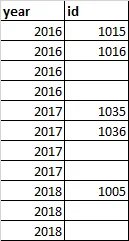
我有一个数据框,看起来像这样:
这就是我想实现的:
但是我遇到了一个错误:
这就是我想实现的:
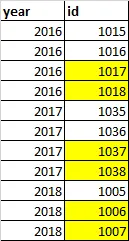
#data
d = {'year': {0: 2016,
1: 2016,
2: 2016,
3: 2016,
4: 2017,
5: 2017,
6: 2017,
7: 2017,
8: 2018,
9: 2018,
10: 2018},
'id': {0: 1015.0,
1: 1016.0,
2: nan,
3: nan,
4: 1035.0,
5: 1036.0,
6: nan,
7: nan,
8: 1005.0,
9: nan,
10: nan}}
# list of years
years = [2016,2017,2018]
# create dataframe
df = pd.DataFrame(d)
# create list that I will append data frames too
l = []
for x in years:
# create a dataframe for each year
df1 = df[df['year']==x].copy()
# fill nans with max value plus 1
df1['id'] = df1['id'].fillna(lambda x: x['id'].max() + 1)
# add dataframe to list
l.append(df1)
# concat list of dataframes
final = pd.concat(l)
这将nans替换为以下文本:
function at 0x000002201F43CB70
我还尝试在我的for循环中使用以下内容:
df1['id'] = df1['id'].apply(lambda x: x['id'].fillna(x['id'].max() +1))
但是我遇到了一个错误:
TypeError: 'float' object is not subscriptable