[原始问题]
我需要一个方程,根据以下数据,曲线随着时间的增长而无限增加。如何得到该方程?
[问题更新]
我需要为scipy.interpolate.splrep指定适当的参数。有人能帮忙吗?
此外,是否有一种方法可以从b样条系数中得到方程?
[备选问题]
如何使用Fourier级数分解获得拟合?
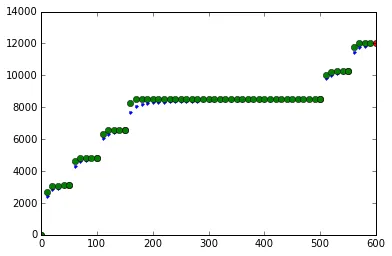
该图似乎是一个线性图的组合,一个周期函数pf1增加了四倍,一个更大的周期函数导致pf1无限地发生。这个问题被提出的原因是该图的困难。
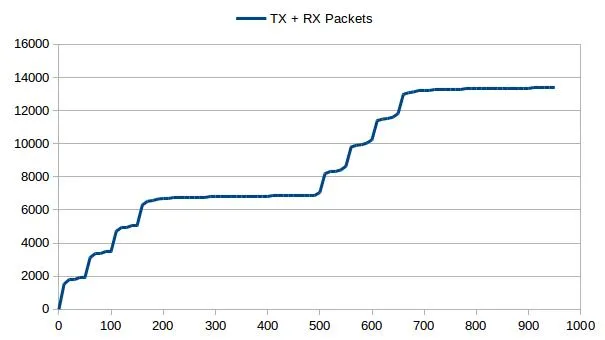
数据:
Time elapsed in sec. TX + RX Packets
(0,0)
(10,2422)
(20,2902)
(30,2945)
(40,3059)
(50,3097)
(60,4332)
(70,4622)
(80,4708)
(90,4808)
(100,4841)
(110,6081)
(120,6333)
(130,6461)
(140,6561)
(150,6585)
(160,7673)
(170,8091)
(180,8210)
(190,8291)
(200,8338)
(210,8357)
(220,8357)
(230,8414)
(240,8414)
(250,8414)
(260,8414)
(270,8414)
(280,8414)
(290,8471)
(300,8471)
(310,8471)
(320,8471)
(330,8471)
(340,8471)
(350,8471)
(360,8471)
(370,8471)
(380,8471)
(390,8471)
(400,8471)
(410,8471)
(420,8528)
(430,8528)
(440,8528)
(450,8528)
(460,8528)
(470,8528)
(480,8528)
(490,8528)
(500,8528)
(510,9858)
(520,10029)
(530,10129)
(540,10224)
(550,10267)
(560,11440)
(570,11773)
(580,11868)
(590,11968)
(600,12039)
(610,13141)
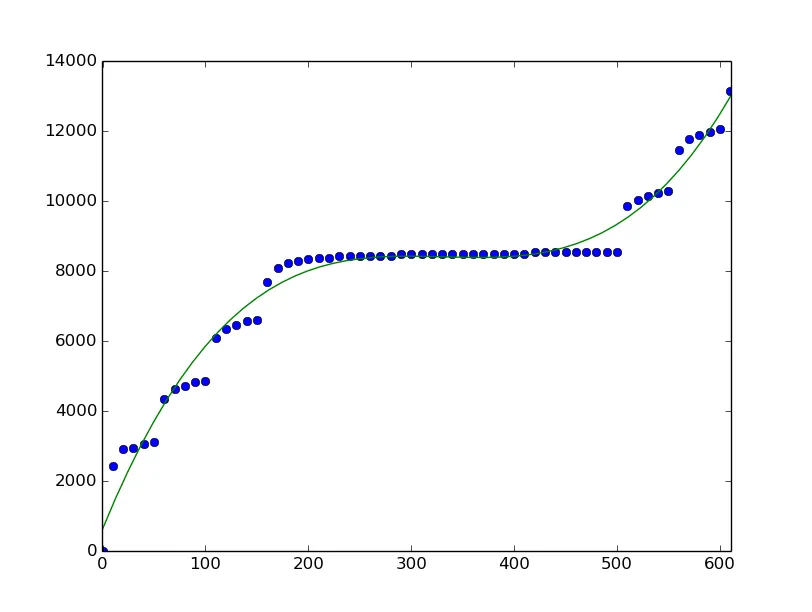
我的代码:
import numpy as np
import matplotlib.pyplot as plt
points = np.array(
[(0,0), (10,2422), (20,2902), (30,2945), (40,3059), (50,3097), (60,4332), (70,4622), (80,4708), (90,4808), (100,4841), (110,6081), (120,6333), (130,6461), (140,6561), (150,6585), (160,7673), (170,8091), (180,8210), (190,8291), (200,8338), (210,8357), (220,8357), (230,8414), (240,8414), (250,8414), (260,8414), (270,8414), (280,8414), (290,8471), (300,8471), (310,8471), (320,8471), (330,8471), (340,8471), (350,8471), (360,8471), (370,8471), (380,8471), (390,8471), (400,8471), (410,8471), (420,8528), (430,8528), (440,8528), (450,8528), (460,8528), (470,8528), (480,8528), (490,8528), (500,8528), (510,9858), (520,10029), (530,10129), (540,10224), (550,10267), (560,11440), (570,11773), (580,11868), (590,11968), (600,12039), (610,13141)]
)
# get x and y vectors
x = points[:,0]
y = points[:,1]
# calculate polynomial
z = np.polyfit(x, y, 3)
print z
f = np.poly1d(z)
# calculate new x's and y's
x_new = np.linspace(x[0], x[-1], 50)
y_new = f(x_new)
plt.plot(x,y,'o', x_new, y_new)
plt.xlim([x[0]-1, x[-1] + 1 ])
plt.show()
我的输出:
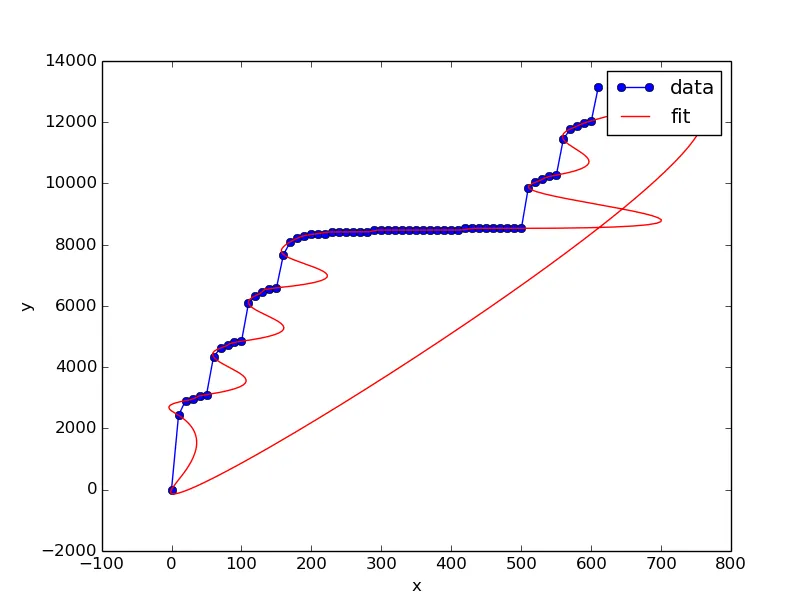
我的代码2:
import numpy as N
from scipy.interpolate import splprep, splev
x = N.array([0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290, 300, 310, 320, 330, 340, 350, 360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490, 500, 510, 520, 530, 540, 550, 560, 570, 580, 590, 600, 610])
y = N.array([0, 2422, 2902, 2945, 3059, 3097, 4332, 4622, 4708, 4808, 4841, 6081, 6333, 6461, 6561, 6585, 7673, 8091, 8210, 8291, 8338, 8357, 8357, 8414, 8414, 8414, 8414, 8414, 8414, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8471, 8528, 8528, 8528, 8528, 8528, 8528, 8528, 8528, 8528, 9858, 10029, 10129, 10224, 10267, 11440, 11773, 11868, 11968, 12039, 13141])
# spline parameters
s=1.0 # smoothness parameter
k=3 # spline order
nest=-1 # estimate of number of knots needed (-1 = maximal)
# find the knot points
tckp,u = splprep([x,y],s=s,k=k,nest=nest,quiet=True,per=1)
# evaluate spline, including interpolated points
xnew,ynew = splev(N.linspace(0,1,400),tckp)
import pylab as P
data,=P.plot(x,y,'bo-',label='data')
fit,=P.plot(xnew,ynew,'r-',label='fit')
P.legend()
P.xlabel('x')
P.ylabel('y')
P.show()
我的输出2:
(注:该内容无需翻译,已为中文)
scipy.interpolate.splrep和per=1可能更简单。 - rth