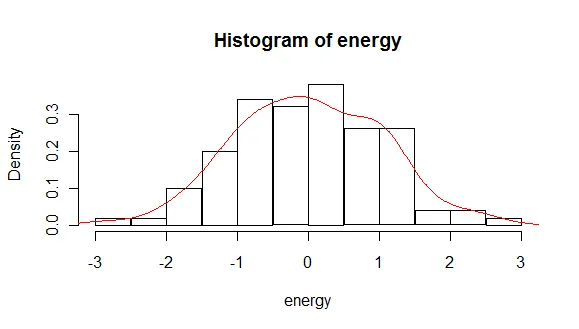
根据我的观察,你的数据似乎不是离散的。在处理连续数据时期望得到概率是明显错误的。density()函数提供了一个经验密度函数,它近似于真实密度函数。为了证明它是正确的密度,我们计算曲线下的面积:
energy <- rnorm(100)
dens <- density(energy)
sum(dens$y)*diff(dens$x[1:2])
[1] 1.000952
由于存在一定的舍入误差,曲线下的面积总和为1,因此density()函数的输出满足概率密度函数(PDF)的要求。
使用hist函数的probability=TRUE选项或者density()函数(或两者兼用)。
例如:
hist(energy,probability=TRUE)
lines(density(energy),col="red")
提供
如果你真的需要一个离散变量的概率,你可以使用:
x <- sample(letters[1:4],1000,replace=TRUE)
prop.table(table(x))
x
a b c d
0.244 0.262 0.275 0.219
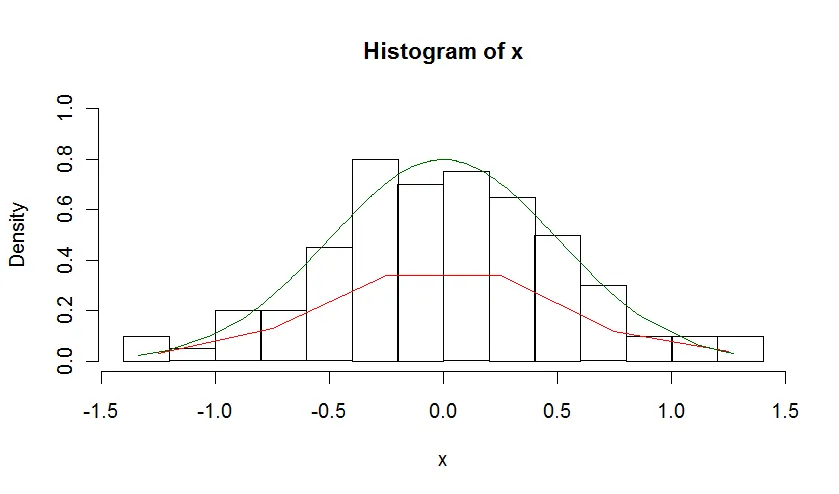
编辑:说明为什么天真的count(x)/sum(count(x))不是一个解决方案。实际上,它之所以不是解决方案,是因为箱子的值加起来等于一,并不意味着曲线下面积也等于一。为了得到曲线下面积,你必须乘以“箱子”的宽度。以正态分布为例,我们可以使用dnorm()计算PDF。以下代码构造了一个正态分布,计算了密度,并将其与天真的解决方案进行了比较:
x <- sort(rnorm(100,0,0.5))
h <- hist(x,plot=FALSE)
dens1 <- h$counts/sum(h$counts)
dens2 <- dnorm(x,0,0.5)
hist(x,probability=TRUE,breaks="fd",ylim=c(0,1))
lines(h$mids,dens1,col="red")
lines(x,dens2,col="darkgreen")
提供:
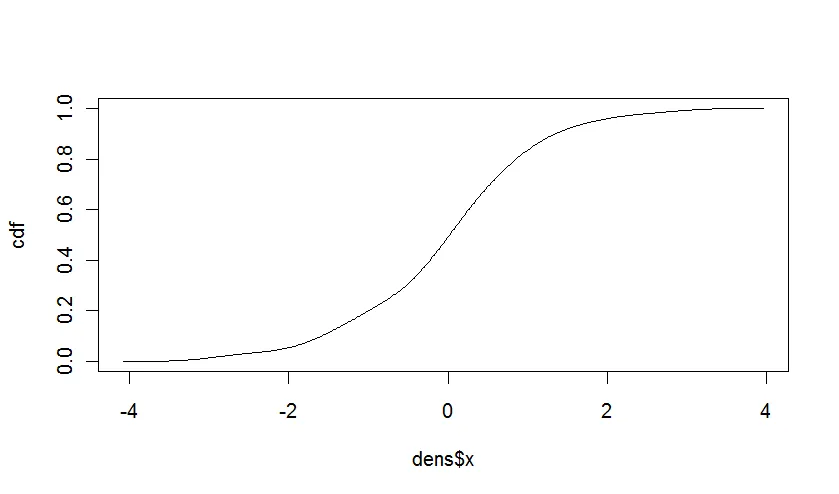
累积分布函数
如果@Iterator是正确的,那么从密度构造累积分布函数就相当容易了。CDF是PDF的积分。对于离散值,这仅仅是概率的总和。对于连续值,我们可以利用估计经验密度的间隔相等的事实,计算如下:
cdf <- cumsum(dens$y * diff(dens$x[1:2]))
cdf <- cdf / max(cdf)
plot(dens$x,cdf,type="l")
给出: