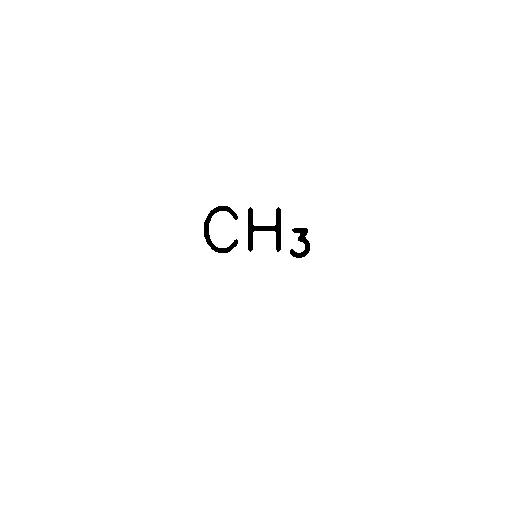
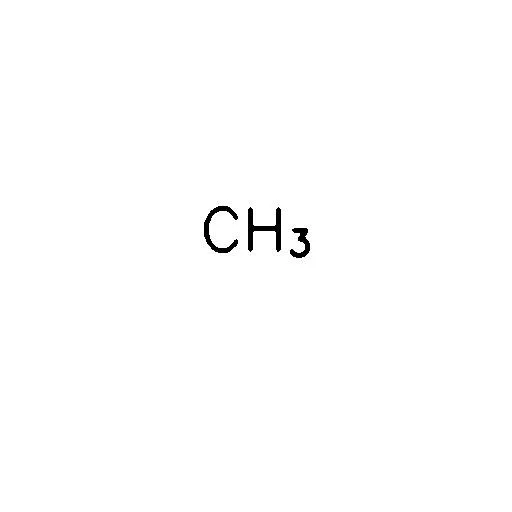
我正在使用tesseract进行OCR,通过pytesseract绑定。不幸的是,当尝试提取包括下标式数字的文本时,下标数字被解释为字母。
例如,在基本图像中:
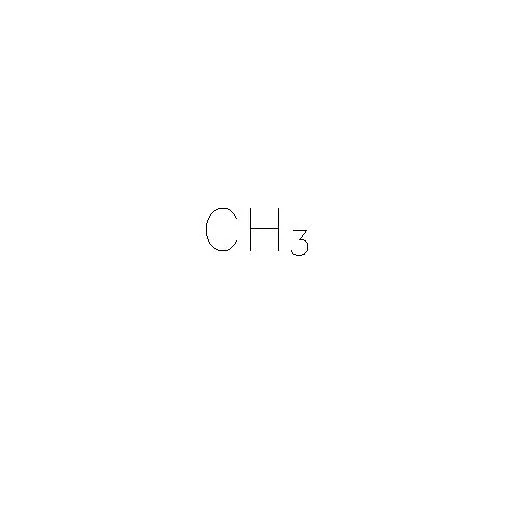
我想提取文本作为“CH3”,即我不关心数字3在图像中是下标。
我使用tesseract的尝试是:
import cv2
import pytesseract
img = cv2.imread('test.jpeg')
# Note that I have reduced the region of interest to the known
# text portion of the image
text = pytesseract.image_to_string(
img[200:300, 200:320], config='-l eng --oem 1 --psm 13'
)
print(text)
不幸的是,这将会错误地输出
'CHs'
根据psm参数的不同,也可能会得到'CHa'。
我怀疑这个问题与文本的“基线”在整行中不一致有关,但我不确定。
如何准确地从这种类型的图像中提取文本?
更新-2020年5月19日
在看到Achintha Ihalage的答案之后(该答案没有为tesseract提供任何配置选项),我探索了psm选项。
由于感兴趣的区域已知(在这种情况下,我使用EAST检测来定位文本的边界框),因此tesseract的psm配置选项,在我的原始代码中将文本视为单行,可能不是必需的。针对上面给出的边界框的感兴趣区域运行image_to_string即可得到输出。
CH
3
它当然可以轻易地被处理,以得到 CH3。