我使用以下代码将一些音频文件转换为了频谱图,并将它们保存到文件中:
import os
from matplotlib import pyplot as plt
import librosa
import librosa.display
import IPython.display as ipd
audio_fpath = "./audios/"
spectrograms_path = "./spectrograms/"
audio_clips = os.listdir(audio_fpath)
def generate_spectrogram(x, sr, save_name):
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
fig = plt.figure(figsize=(20, 20), dpi=1000, frameon=False)
ax = fig.add_axes([0, 0, 1, 1], frameon=False)
ax.axis('off')
librosa.display.specshow(Xdb, sr=sr, cmap='gray', x_axis='time', y_axis='hz')
plt.savefig(save_name, quality=100, bbox_inches=0, pad_inches=0)
librosa.cache.clear()
for i in audio_clips:
audio_fpath = "./audios/"
spectrograms_path = "./spectrograms/"
audio_length = librosa.get_duration(filename=audio_fpath + i)
j=60
while j < audio_length:
x, sr = librosa.load(audio_fpath + i, offset=j-60, duration=60)
save_name = spectrograms_path + i + str(j) + ".jpg"
generate_spectrogram(x, sr, save_name)
j += 60
if j >= audio_length:
j = audio_length
x, sr = librosa.load(audio_fpath + i, offset=j-60, duration=60)
save_name = spectrograms_path + i + str(j) + ".jpg"
generate_spectrogram(x, sr, save_name)
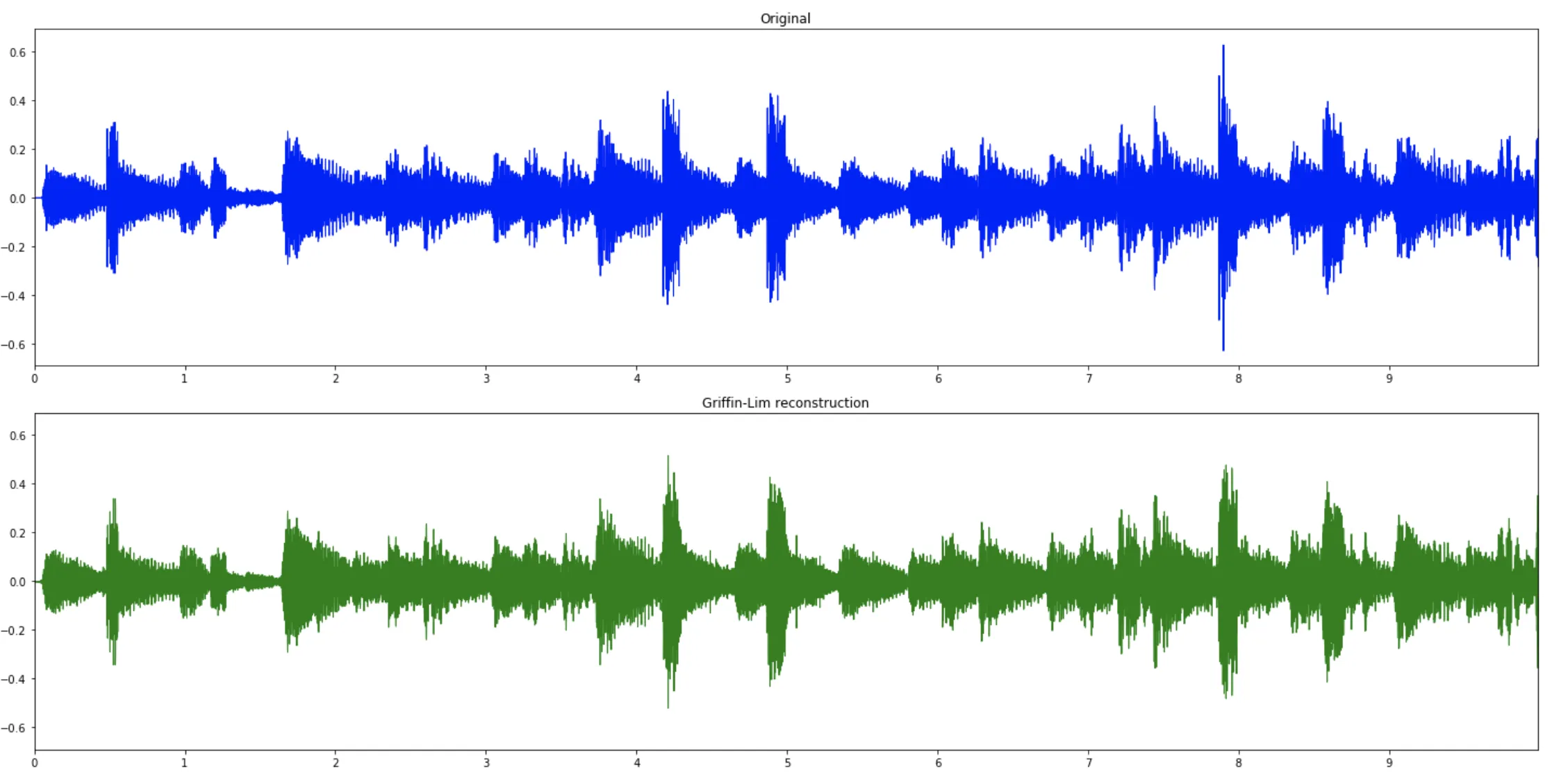
我希望保留音频的最多细节和质量,这样以后转换回音频时就不会有太大的损失(它们每个约为80MB)。
能否将它们转换回音频文件?我该怎么做呢?
我尝试使用librosa.feature.inverse.mel_to_audio,但它没有起作用,并且我认为它不适用。
现在我有1300个光谱图文件并想用它们来训练生成对抗网络,以便可以生成新的音频,但如果我以后无法听到结果,我就不想这样做。