我使用Kaldi的"egs/tidigits"代码,使用23个频段、20kHz采样率、25毫秒窗口和10毫秒移位,生成了一个"seven"发音的频谱图。通过MATLAB的imagesc函数可视化,频谱图如下所示:
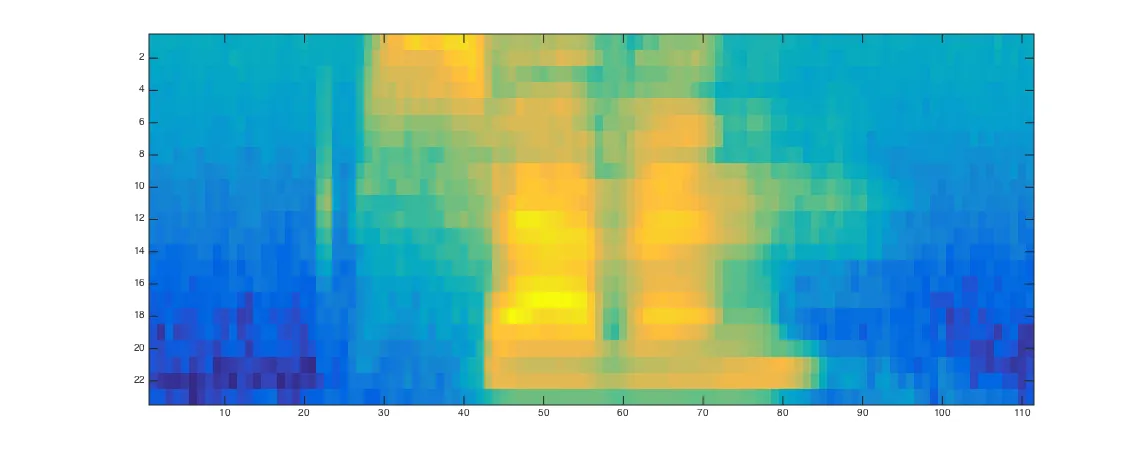
我正在尝试使用Librosa作为Kaldi的替代品。我使用与上述相同数量的频段、采样率、窗口长度和移位设置了我的代码。
time_series, sample_rate = librosa.core.load("7a.wav",sr=20000)
spectrogram = librosa.feature.melspectrogram(time_series, sr=20000, n_mels=23, n_fft=500, hop_length=200)
log_S = librosa.core.logamplitude(spectrogram)
np.savetxt("7a.txt", log_S.T)
然而,当我将相同的WAV文件进行Librosa频谱图可视化时,它看起来不同:
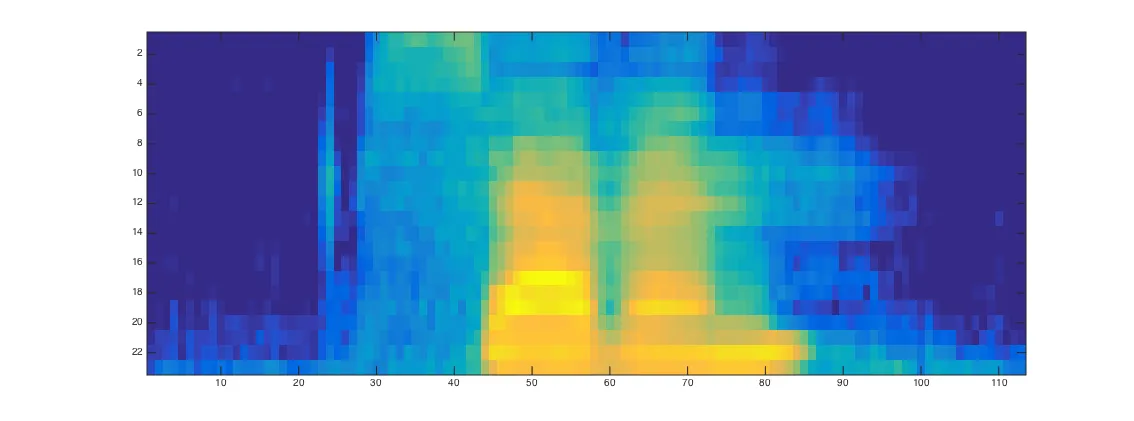
请问有人能帮我理解为什么它们看起来如此不同吗?通过其他我尝试过的WAV文件,我注意到在上面的脚本中,我的摩擦音(例如“seven”中的/s/)被截断,这极大地影响了我的数字分类准确性。谢谢!