我正在尝试绘制16000Hz 16位.wav语音音频的波形图和频谱图。我已成功获得以下绘图: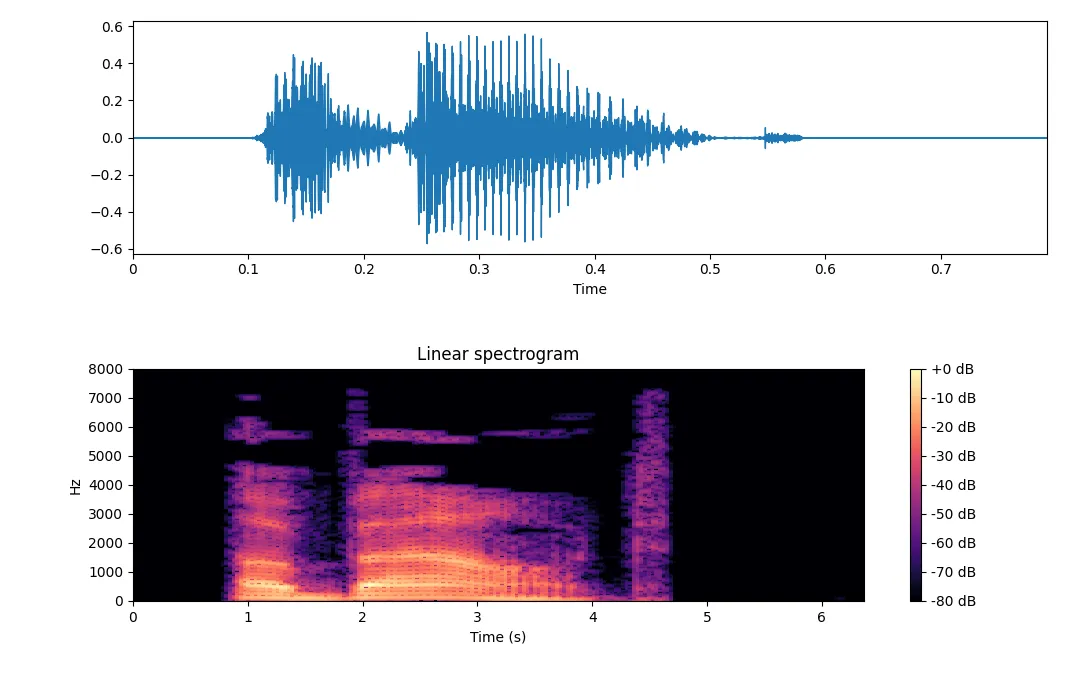 然而,频谱图上的时间值不正确。我确定程序中采样率始终为16000Hz,但仍无法获得正确的频谱图时间值。我的python脚本如下:
然而,频谱图上的时间值不正确。我确定程序中采样率始终为16000Hz,但仍无法获得正确的频谱图时间值。我的python脚本如下:
我不知道我漏掉了什么可以导致x轴上的时间值不一致。请帮忙。
然而,频谱图上的时间值不正确。我确定程序中采样率始终为16000Hz,但仍无法获得正确的频谱图时间值。我的python脚本如下:import matplotlib.pyplot as plt
import librosa
import librosa.display
import numpy as np
y, sr = librosa.load('about_TTS_0792.wav', sr=16000)
print("Current audio sampling rate: ", sr)
print("Audio Duration:", librosa.get_duration(y=y, sr=sr))
D = librosa.stft(y, hop_length=64, win_length=256) # STFT of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
fig, ax = plt.subplots(nrows=2)
librosa.display.waveplot(y, sr=sr, ax=ax[0])
img = librosa.display.specshow(S_db, sr=sr, x_axis='s', y_axis='linear',ax=ax[1])
ax[1].set(title='Linear spectrogram')
fig.colorbar(img, ax=ax[1], format="%+2.f dB")
fig.tight_layout()
plt.show()
这段代码的输出结果:
Current audio sampling rate: 16000
Audio Duration: 0.792
我不知道我漏掉了什么可以导致x轴上的时间值不一致。请帮忙。