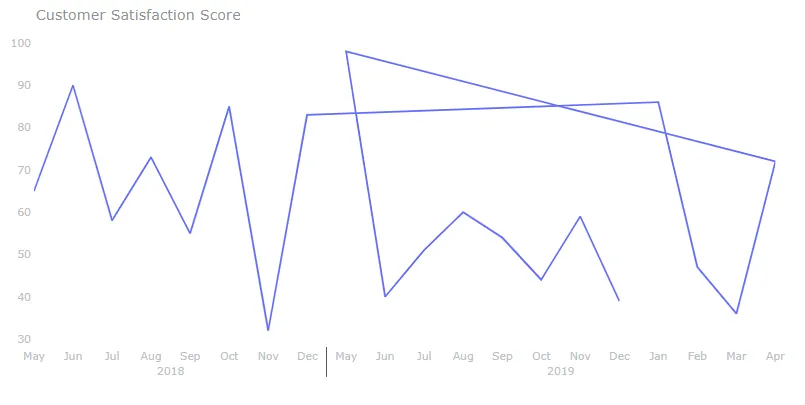
我正在尝试创建一个带有日期的多类别x轴,下面的代码和图表展示了我想要的外观,但是它的顺序错乱了。我尝试使用“原始x轴”列代替月份,但是格式不正确,我似乎无法更改它的格式。
import random
import numpy as np
import plotly.express as px
df = pd.DataFrame({"Year":np.repeat([2018,2019],[8,12]),
"Month": ["May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec", "Jan", "Feb", "Mar", "Apr","May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"],
"Original x-axis": pd.date_range(start = "2018-05-01", end = "2019-12-01", freq = "MS"),
"Customer Satisfaction Score": random.sample(range(30,100), 20)})
fig = go.Figure()
fig.add_trace(go.Scatter(
#x = cust["Original x-axis"],
x = [df["Year"],df["Month"]],
y = df["Customer Satisfaction Score"], mode = "lines"))
fig.update_layout(plot_bgcolor = "white",
annotations = [dict(text = "Customer Satisfaction Score",
yref = "paper",
xref = "paper",
x = 0,
y = 1.1,
font = dict(size = 16, color = "#909497"),
showarrow = False)],
font = dict(size = 12, color = "#BDC3C7"))
#xaxis = dict(tickformat = "%b"))
fig.show()