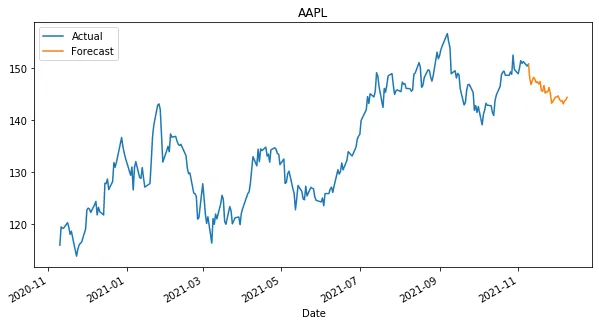
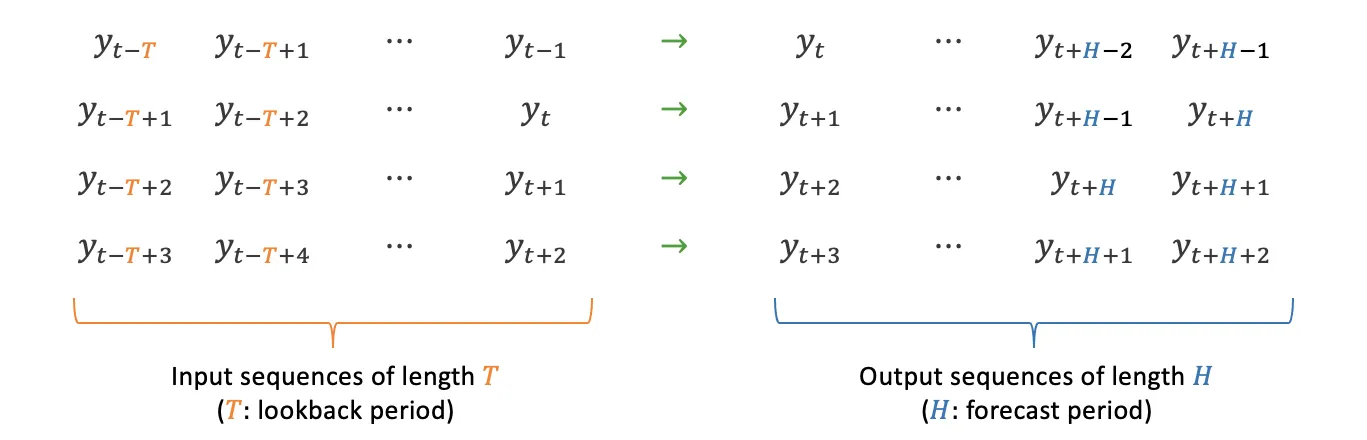这段代码可以预测指定股票的值,预测时间仅限于当前日期,不能超过训练数据集中的日期。该代码来自我之前提出的一个问题,所以我对它的理解很低。我猜想解决方法可能只需要改变简单的变量,以增加额外的时间,但我不知道应该改变哪个值。
import pandas as pd
import numpy as np
import yfinance as yf
import os
import matplotlib.pyplot as plt
from IPython.display import display
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
pd.options.mode.chained_assignment = None
# download the data
df = yf.download(tickers=['AAPL'], period='2y')
# split the data
train_data = df[['Close']].iloc[: - 200, :]
valid_data = df[['Close']].iloc[- 200:, :]
# scale the data
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(train_data)
train_data = scaler.transform(train_data)
valid_data = scaler.transform(valid_data)
# extract the training sequences
x_train, y_train = [], []
for i in range(60, train_data.shape[0]):
x_train.append(train_data[i - 60: i, 0])
y_train.append(train_data[i, 0])
x_train = np.array(x_train)
y_train = np.array(y_train)
# extract the validation sequences
x_valid = []
for i in range(60, valid_data.shape[0]):
x_valid.append(valid_data[i - 60: i, 0])
x_valid = np.array(x_valid)
# reshape the sequences
x_train = x_train.reshape(x_train.shape[0],
x_train.shape[1], 1)
x_valid = x_valid.reshape(x_valid.shape[0],
x_valid.shape[1], 1)
# train the model
model = Sequential()
model.add(LSTM(units=50, return_sequences=True,
input_shape=x_train.shape[1:]))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=50, batch_size=128, verbose=1)
# generate the model predictions
y_pred = model.predict(x_valid)
y_pred = scaler.inverse_transform(y_pred)
y_pred = y_pred.flatten()
# plot the model predictions
df.rename(columns={'Close': 'Actual'}, inplace=True)
df['Predicted'] = np.nan
df['Predicted'].iloc[- y_pred.shape[0]:] = y_pred
df[['Actual', 'Predicted']].plot(title='AAPL')
display(df)
plt.show()