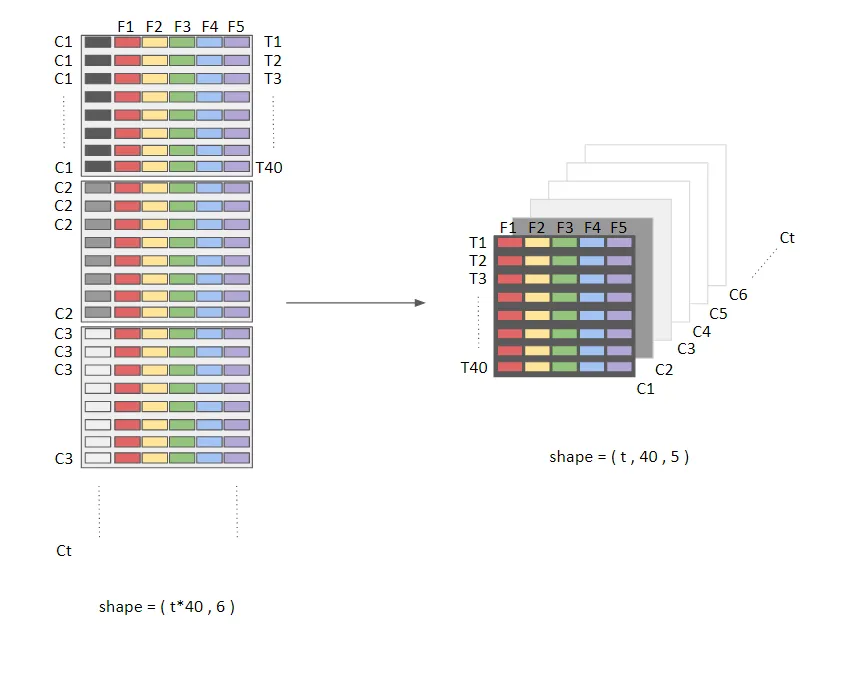
我有一个形状为(t*40,6)的二维数组,我想将其转换为形状为(t,40,5)的三维数组,用于LSTM的输入数据层。如下图所示,描述了所需的转换方式。这里,F1..5是5个输入特征,T1...40是LSTM的时间步长,C1...t是各种训练示例。基本上,对于每个唯一的“Ct”,我都希望有一个“T X F”的二维数组,并沿第3个维度进行连接。只要每个Ct在不同的维度中即可,我不介意失去“Ct”的值。
然而,有超过180万个这样的Ct,因此循环遍历每个唯一的Ct会相当缓慢。寻求如何更快地执行此操作的建议。
编辑:
这是原始问题的解决方案。
更新问题并增加一个问题:T1...40个时间步骤可以有最高40步,但也可能少于40步。其余的值可以在可用的40个插槽中为'np.nan'。
# load 2d data
data = pd.read_csv('LSTMTrainingData.csv')
trainX = []
# loop over each unique ct and append the 2D subset in the 3rd dimension
for index, ct in enumerate(data.ct.unique()):
trainX.append(data[data['ct'] == ct].iloc[:, 1:])
然而,有超过180万个这样的Ct,因此循环遍历每个唯一的Ct会相当缓慢。寻求如何更快地执行此操作的建议。
编辑:
data_3d = array.reshape(t,40,6)
trainX = data_3d[:,:,1:]
这是原始问题的解决方案。
更新问题并增加一个问题:T1...40个时间步骤可以有最高40步,但也可能少于40步。其余的值可以在可用的40个插槽中为'np.nan'。