如何修改 pandas 中 groupby 操作输出的科学计数法格式以适应极大数字?
我知道如何在 Python 中进行字符串格式化,但是在这里应用它时感到困惑。
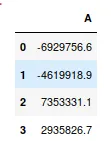
df1.groupby('dept')['data1'].sum()
dept
value1 1.192433e+08
value2 1.293066e+08
value3 1.077142e+08
如果我将其转换为字符串,这将抑制科学计数法,但现在我想知道如何格式化字符串并添加小数点。
sum_sales_dept.astype(str)
dtypes是什么? - TomAugspurger