总的来说,我不建议尝试击败NumPy。对于长数组而言,很少有人能够竞争,更难得的是找到一个更快的实现方式。即使速度更快,也可能最多只比NumPy快2倍。所以这种情况很少值得一试。
然而,最近我自己尝试了类似的事情,因此我可以分享一些有趣的结果。
我并不是自己想出来的。我基于 numba (re-) 实现的np.median 的方法。他们可能知道他们在做什么。
我最终得到的结果是:
import numba as nb
import numpy as np
@nb.njit
def _partition(A, low, high):
"""copied from numba source code"""
mid = (low + high) >> 1
if A[mid] < A[low]:
A[low], A[mid] = A[mid], A[low]
if A[high] < A[mid]:
A[high], A[mid] = A[mid], A[high]
if A[mid] < A[low]:
A[low], A[mid] = A[mid], A[low]
pivot = A[mid]
A[high], A[mid] = A[mid], A[high]
i = low
for j in range(low, high):
if A[j] <= pivot:
A[i], A[j] = A[j], A[i]
i += 1
A[i], A[high] = A[high], A[i]
return i
@nb.njit
def _select_lowest(arry, k, low, high):
"""copied from numba source code, slightly changed"""
i = _partition(arry, low, high)
while i != k:
if i < k:
low = i + 1
i = _partition(arry, low, high)
else:
high = i - 1
i = _partition(arry, low, high)
return arry[:k]
@nb.njit
def _nlowest_inner(temp_arry, n, idx):
"""copied from numba source code, slightly changed"""
low = 0
high = n - 1
return _select_lowest(temp_arry, idx, low, high)
@nb.njit
def nlowest(a, idx):
"""copied from numba source code, slightly changed"""
temp_arry = a.flatten()
n = temp_arry.shape[0]
return _nlowest_inner(temp_arry, n, idx)
在计时之前,我加入了一些热身调用。热身是为了不将编译时间算入计时中:
rselect(np.random.rand(10), 5)
nlowest(np.random.rand(10), 5)
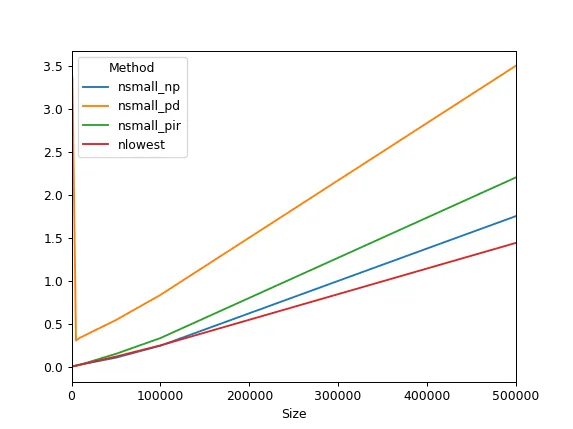
由于我的计算机速度较慢,我稍微改变了元素数量和重复次数。但结果似乎表明,我(或者说numba开发人员)已经击败了NumPy:
results = pd.DataFrame(
index=pd.Index([100, 500, 1000, 5000, 10000, 50000, 100000, 500000], name='Size'),
columns=pd.Index(['nsmall_np', 'nsmall_pd', 'nsmall_pir', 'nlowest'], name='Method')
)
rselect(np.random.rand(10), 5)
nlowest(np.random.rand(10), 5)
for i in results.index:
x = np.random.rand(i)
n = i // 2
for j in results.columns:
stmt = '{}(x, n)'.format(j)
setp = 'from __main__ import {}, x, n'.format(j)
results.set_value(i, j, timeit(stmt, setp, number=100))
print(results)
Method nsmall_np nsmall_pd nsmall_pir nlowest
Size
100 0.00343059 0.561372 0.00190855 0.000935566
500 0.00428461 1.79398 0.00326862 0.00187225
1000 0.00560669 3.36844 0.00432595 0.00364284
5000 0.0132515 0.305471 0.0142569 0.0108995
10000 0.0255161 0.340215 0.024847 0.0248285
50000 0.105937 0.543337 0.150277 0.118294
100000 0.2452 0.835571 0.333697 0.248473
500000 1.75214 3.50201 2.20235 1.44085
![[1]: https://i.stack.imgur.com/hKo2o](https://istack.dev59.com/D1gqQ.webp)
njit协同工作? - piRSquared_partition函数只是被简单地复制了,_select函数只在最后一行进行了更改(将arry[k]替换为arry[:k])。另外两个函数进行了更多的更改:我更改了函数名称,用新的idx参数替换了mid部分,并删除了处理偶数长度数组中位数的部分。nlowest函数最初是median_impl函数。此外,我将@register_jitable更改为@njit,并且不需要(也不想要)@overload。说实话,这条注释写起来可能比更改numba源代码还要花费更多时间。:D - MSeifertnumba的高级用户了。谢谢分享 :-) - piRSquared