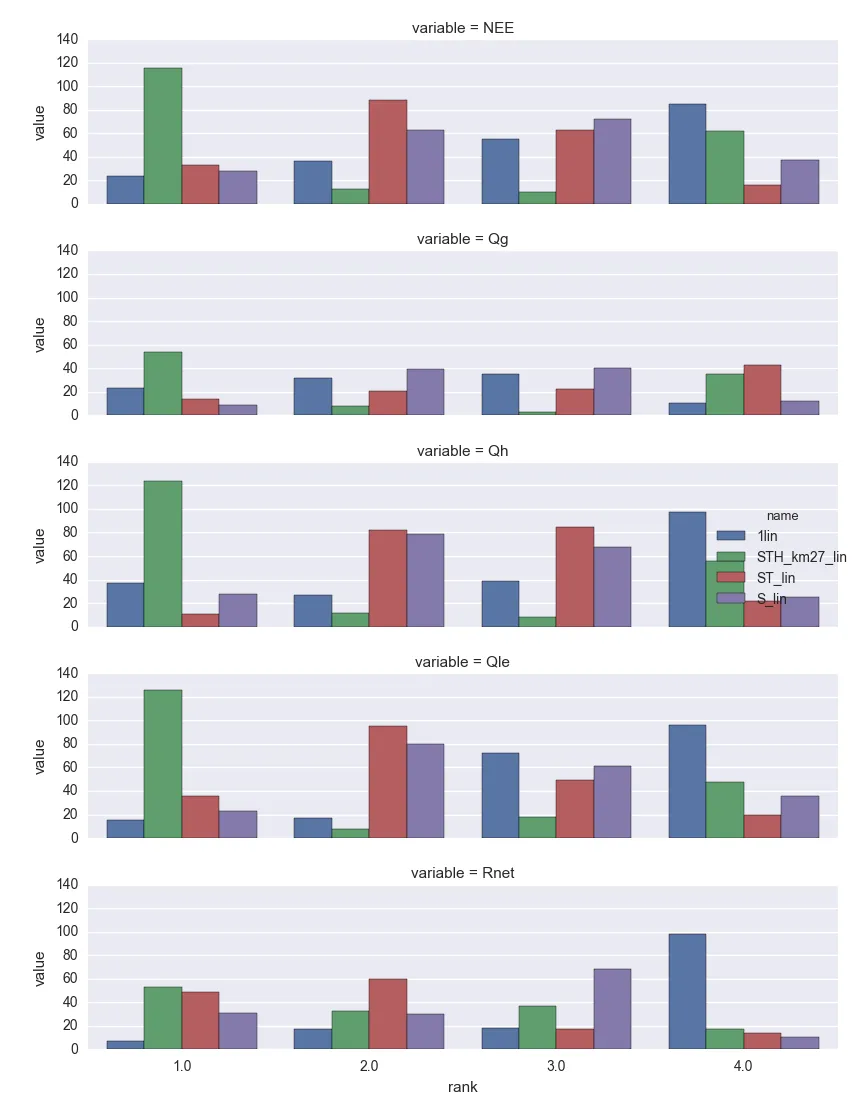
目前这段代码:
count_df = (df[['rank', 'name', 'variable', 'value']]
.groupby(['rank', 'variable', 'name'])
.agg('count')
.unstack())
count_df .head()
# value
# name 1lin STH_km27_lin ST_lin S_lin
# rank variable
# 1.0 NEE 24 115 33 28
# Qg 23 54 14 9
# Qh 37 124 11 28
# ...
count_df.plot(kind='bar')
得到这个情节:
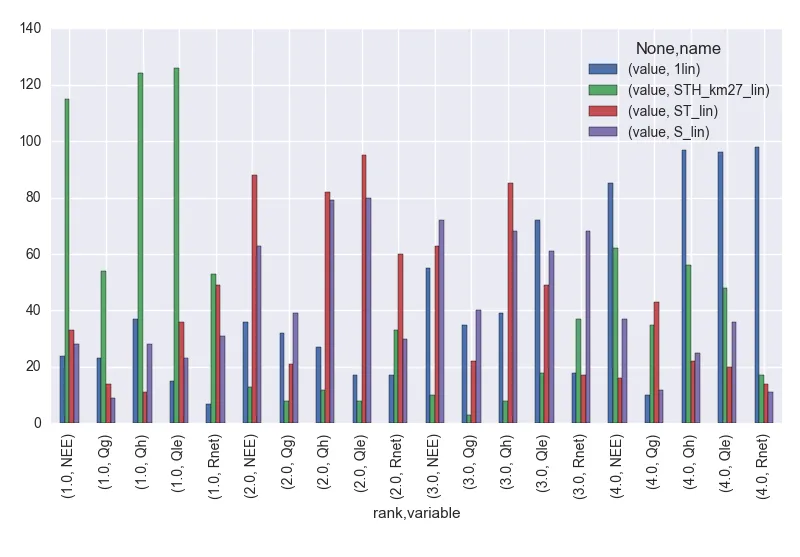
.plot()调用中使用subplots=True会得到这样的结果:
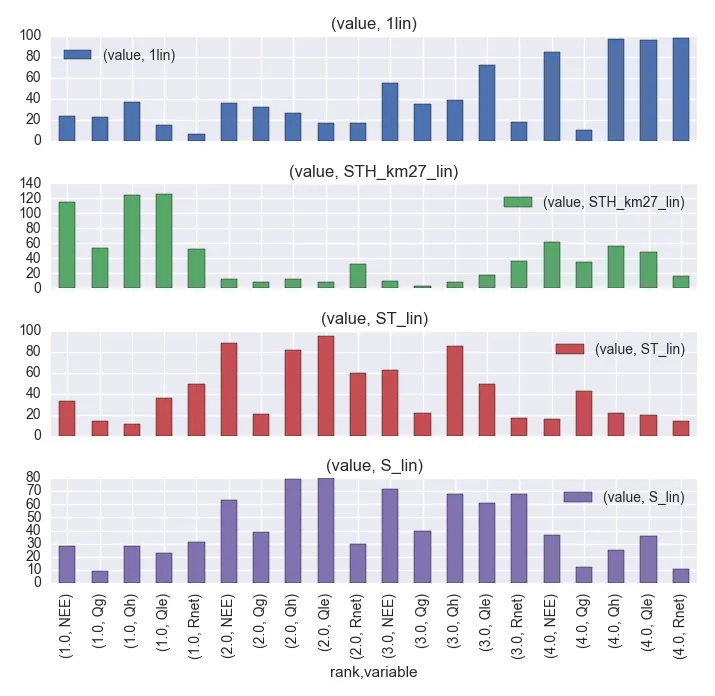
name(count_df列标题)进行着色,但是按variable进行子图分面,以便每个子图都有一个name/rank条形图,按rank分组,并按name进行着色?