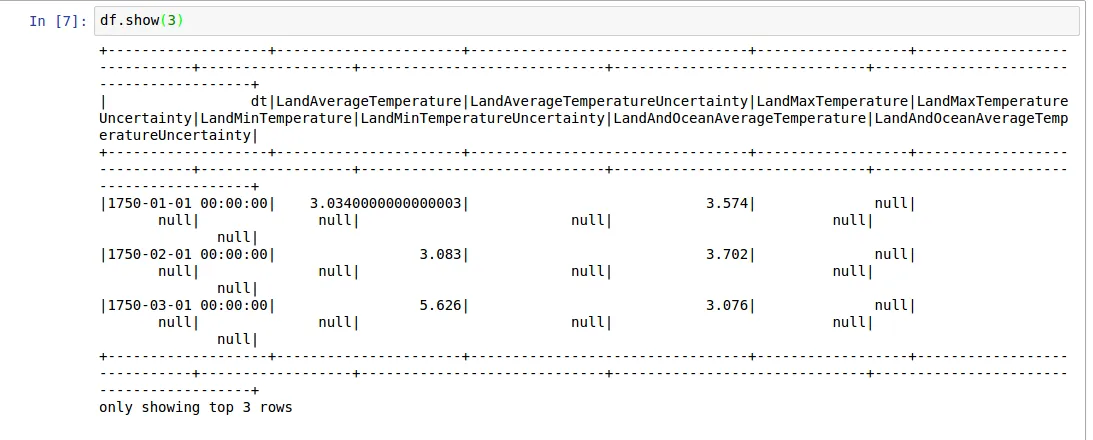
使用 DataFrame.show() 方法显示的 pyspark.sql.DataFrame 显示不整齐 - 行被换行而不是滚动。
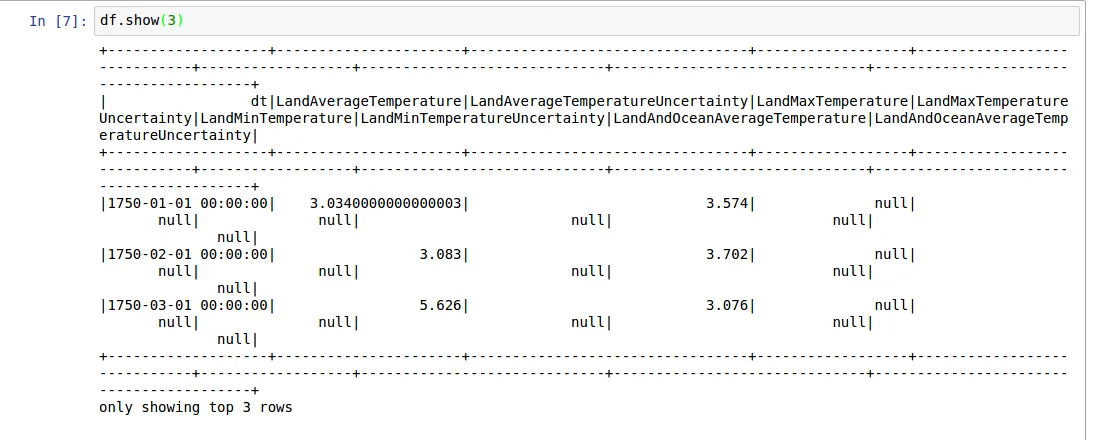
但使用 pandas.DataFrame.head 方法显示则正常。

我尝试了这些选项
import IPython
IPython.auto_scroll_threshold = 9999
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
from IPython.display import display
但是没有运气。尽管使用带有jupyter插件的Atom编辑器时滚动条可以工作:

spark_df_head.toPandas()。 - muon