使用此数据...
我尝试了这条路线,但除了猪之外,还有很多其他物种可以应用于此。 显示图表中的显著差异 我可以一次获取一个区域的字母,但我不确定如何将两个区域添加到图中。它们也是无序的。我修改了来自网页的此代码,字母不能很好地放置在条形图上方。
hogs.sample<-structure(list(Zone = c("B", "B", "B", "B", "B", "B", "B", "B",
"B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "D",
"D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D",
"D", "D", "D", "D", "D", "D"), Levelname = c("Medium", "High",
"Low", "Med.High", "Med.High", "Med.High", "Med.High", "Med.High",
"Med.High", "Medium", "Med.High", "Medium", "Med.High", "High",
"Medium", "High", "Low", "Med.High", "Low", "High", "Medium",
"Medium", "Med.High", "Low", "Low", "Med.High", "Low", "Low",
"High", "High", "Med.High", "High", "Med.High", "Med.High", "Medium",
"High", "Low", "Low", "Med.High", "Low"), hogs.fit = c(-0.122,
-0.871, -0.279, -0.446, 0.413, 0.011, 0.157, 0.131, 0.367, -0.23,
0.007, 0.05, 0.04, -0.184, -0.265, -1.071, -0.223, 0.255, -0.635,
-1.103, 0.008, -0.04, 0.831, 0.042, -0.005, -0.022, 0.692, 0.402,
0.615, 0.785, 0.758, 0.738, 0.512, 0.222, -0.424, 0.556, -0.128,
-0.495, 0.591, 0.923)), row.names = c(NA, -40L), groups = structure(list(
Zone = c("B", "D"), .rows = structure(list(1:20, 21:40), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, -2L), class = c("tbl_df",
"tbl", "data.frame"), .drop = TRUE), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"))
我试图根据Tukey的HSD方法在下面的图中添加重要性字母...
library(agricolae)
library(tidyverse)
hogs.plot <- ggplot(hogs.sample, aes(x = Zone, y = exp(hogs.fit),
fill = factor(Levelname, levels = c("High", "Med.High", "Medium", "Low")))) +
stat_summary(fun = mean, geom = "bar", position = position_dodge(0.9), color = "black") +
stat_summary(fun.data = mean_se, geom = "errorbar", position = position_dodge(0.9), width = 0.2) +
labs(x = "", y = "CPUE (+/-1SE)", legend = NULL) +
scale_y_continuous(expand = c(0,0), labels = scales::number_format(accuracy = 0.1)) +
scale_fill_manual(values = c("midnightblue", "dodgerblue4", "steelblue3", 'lightskyblue')) +
scale_x_discrete(breaks=c("B", "D"), labels=c("Econfina", "Steinhatchee"))+
scale_color_hue(l=40, c = 100)+
# coord_cartesian(ylim = c(0, 3.5)) +
labs(title = "Hogs", x = "", legend = NULL) +
theme(panel.border = element_blank(), panel.grid.major = element_blank(), panel.background = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(),
axis.text.x = element_text(), axis.title.x = element_text(vjust = 0),
axis.title.y = element_text(size = 8))+
theme(legend.title = element_blank(),
legend.position = "none")
hogs.plot
我的理想输出应该是这样的...
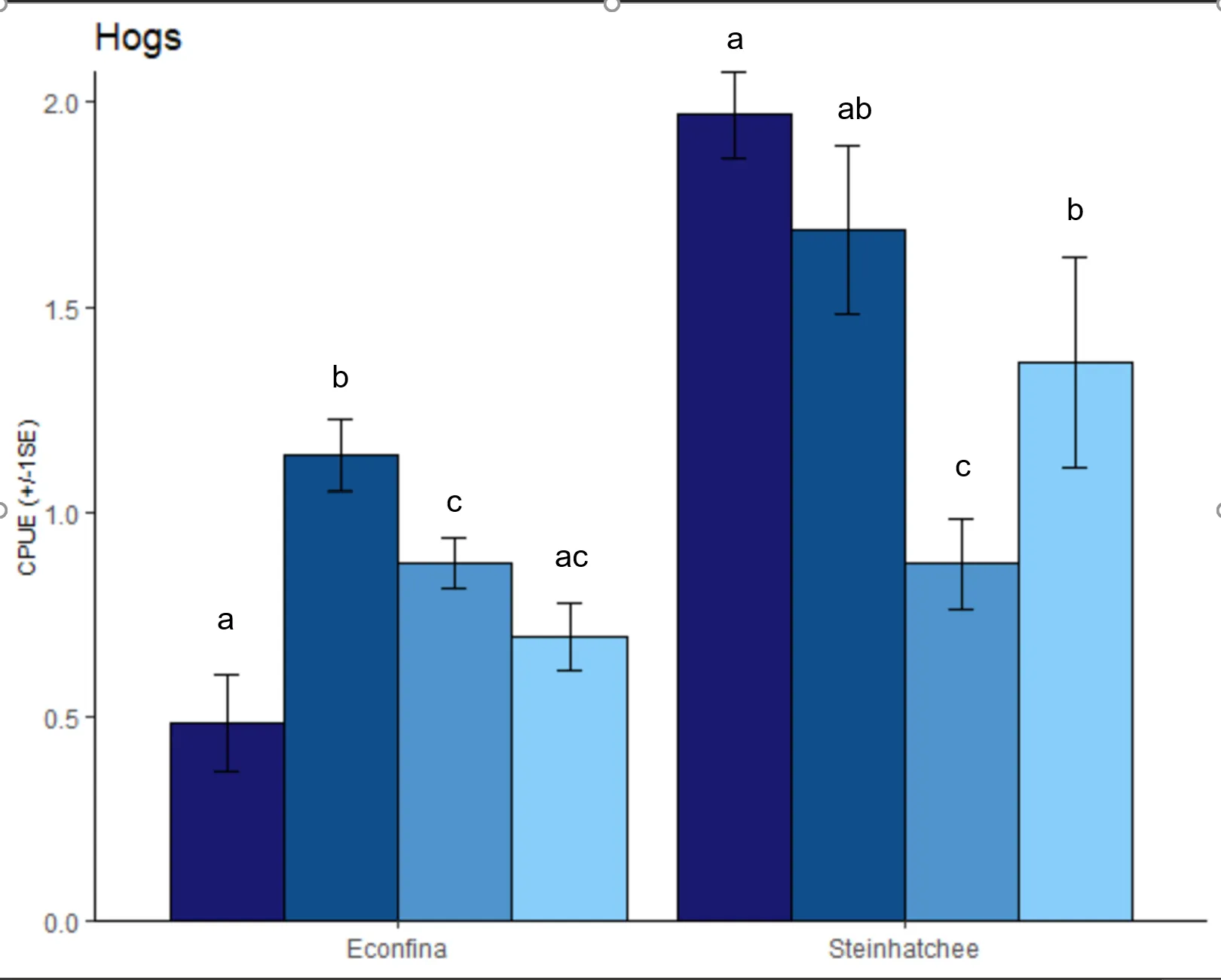
我不确定这些字母在我的样本图中是否完全准确,但它们表示哪些组之间存在显著差异。区域是独立的,所以我不想在两个区域之间进行比较,因此我使用以下代码分别运行它们。
hogs.aov.b <- aov(hogs.fit ~Levelname, data = filter(hogs.sample, Zone == "B"))
hogs.aov.summary.b <- summary(hogs.aov.b)
hogs.tukey.b <- TukeyHSD(hogs.aov.b)
hogs.tukey.b
hogs.aov.d <- aov(hogs.fit ~ Levelname, data = filter(hogs.sample, Zone == "D"))
hogs.aov.summary.d <- summary(hogs.aov.d)
hogs.tukey.d <- TukeyHSD(hogs.aov.d)
hogs.tukey.d
我尝试了这条路线,但除了猪之外,还有很多其他物种可以应用于此。 显示图表中的显著差异 我可以一次获取一个区域的字母,但我不确定如何将两个区域添加到图中。它们也是无序的。我修改了来自网页的此代码,字母不能很好地放置在条形图上方。
library(agricolae)
library(tidyverse)
# get highest point overall
abs_max <- max(bass.dat.d$bass.fit)
# get the highest point for each class
maxs <- bass.dat.d %>%
group_by(Levelname) %>%
# I like to add a little bit to each value so it rests above
# the highest point. Using a percentage of the highest point
# overall makes this code a bit more general
summarise(bass.fit=max(mean(exp(bass.fit))))
# get Tukey HSD results
Tukey_test <- aov(bass.fit ~ Levelname, data=bass.dat.d) %>%
HSD.test("Levelname", group=TRUE) %>%
.$groups %>%
as_tibble(rownames="Levelname") %>%
rename("Letters_Tukey"="groups") %>%
select(-bass.fit) %>%
# and join it to the max values we calculated -- these are
# your new y-coordinates
left_join(maxs, by="Levelname")
还有很多类似的例子,比如https://www.staringatr.com/3-the-grammar-of-graphics/bar-plots/3_tukeys/,但它们都是手动添加文本。有一个能够自动将Tukey输出添加到图表中的代码会很好。
谢谢



n(): ! 必须在dplyr动词内部使用。 运行rlang::last_error()以查看出错的位置。 - nouse