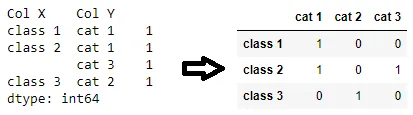
我有一个 Pandas 数据框:
Col X Col Y
class 1 cat 1
class 2 cat 1
class 3 cat 2
class 2 cat 3
我想要转换成:
cat 1 cat 2 cat 3
class 1 1 0 0
class 2 1 0 1
class 3 0 1 0
其中的值是值计数。我该怎么做?
set_index和unstack)通常不起作用:当原始数据中存在重复行时,它会失败。 - Eric O. Lebigot