步骤:
- 从
user_id中提取id_numbers并将它们转换为int类型。
- 使用
groupby和agg来计算count/ucount / frequency。
- 使用
pivot重构表格。
- 如果需要,展开列并使用
reset_index。
df['userid'] = df.userid.str.extract(r'(\d+)').astype(int)
k = df.groupby(["type", 'cid']).agg(count=('userid', 'count'), ucount=(
'userid', 'nunique'), frequency=('userid', lambda x: x.value_counts().to_dict())).reset_index()
k = k.pivot(index=[k.index, 'cid'], columns='type').fillna(0)
输出:
count ucount frequency
type c i c i c i
cid
0 1 1.0 0.0 1.0 0.0 {1: 1} 0
1 1 0.0 3.0 0.0 2.0 0 {1: 2, 2: 1}
2 2 0.0 1.0 0.0 1.0 0 {1: 1}
然后进行列转换:
k.columns = k.columns.map(lambda x: '_'.join(x[::-1]))
输出:
c_count i_count c_ucount i_ucount c_frequency i_frequency
cid
0 1 1.0 0.0 1.0 0.0 {1: 1} 0
1 1 0.0 3.0 0.0 2.0 0 {1: 2, 2: 1}
2 2 0.0 1.0 0.0 1.0 0 {1: 1}
根据您编辑后的问题更新的答案:
k = df.groupby(["type" , 'cid']).agg(count = ('userid' ,'count') , ucount = ('userid', 'nunique') , frequency=('userid', lambda x: x.value_counts().to_dict())).reset_index()
k = k.pivot(index=['cid'], columns ='type').fillna(0)
输出:
count ucount frequency
type c i c i c i
cid
1 1.0 3.0 1.0 2.0 {'userid001': 1} {'userid001': 2, 'userid002': 1}
2 0.0 1.0 0.0 1.0 0 {'userid001': 1}
注意:如果需要编码userid,请使用df.userid = df.userid.factorize()[0]。

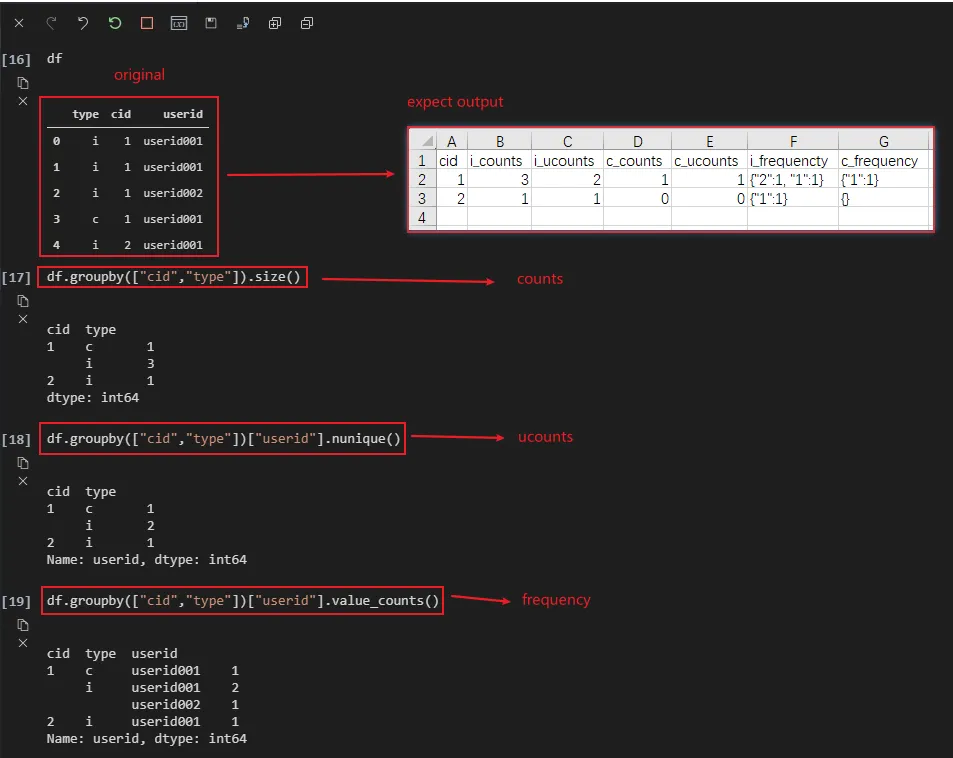
df.groupby(["cid","type"]).agg(counts=("userid", np.size), ucounts=("userid", "nunique")).reset_index(),但不知道如何继续以获得我期望的结果。 - Silence He