实验
我在 Spark 1.6.1 上尝试了以下代码片段。
val soDF = sqlContext.read.parquet("/batchPoC/saleOrder") # This has 45 files
soDF.registerTempTable("so")
sqlContext.sql("select dpHour, count(*) as cnt from so group by dpHour order by cnt").write.parquet("/out/")
物理计划是:
== Physical Plan ==
Sort [cnt#59L ASC], true, 0
+- ConvertToUnsafe
+- Exchange rangepartitioning(cnt#59L ASC,200), None
+- ConvertToSafe
+- TungstenAggregate(key=[dpHour#38], functions=[(count(1),mode=Final,isDistinct=false)], output=[dpHour#38,cnt#59L])
+- TungstenExchange hashpartitioning(dpHour#38,200), None
+- TungstenAggregate(key=[dpHour#38], functions=[(count(1),mode=Partial,isDistinct=false)], output=[dpHour#38,count#63L])
+- Scan ParquetRelation[dpHour#38] InputPaths: hdfs://hdfsNode:8020/batchPoC/saleOrder
针对此查询,我得到了两个作业:Job 9和Job 10

对于Job 9,DAG为:
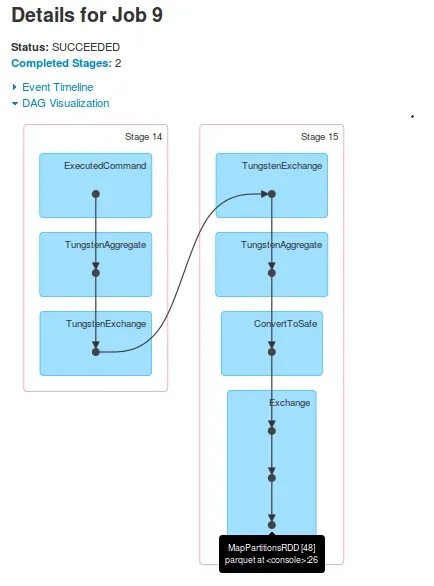
对于Job 10,DAG为:
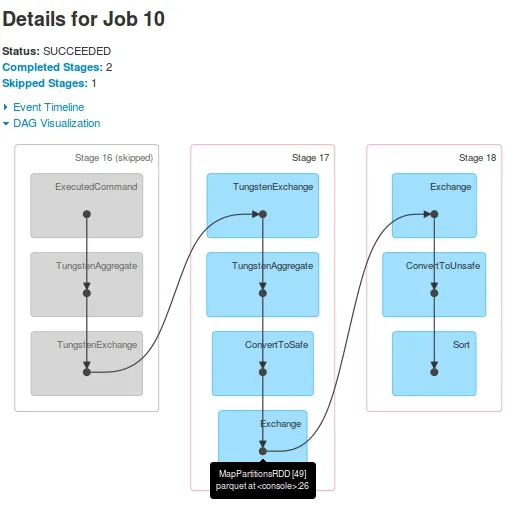
观察
- 显然,一个查询有两个
jobs。 Job 10跳过了Stage-16(在Job 9中标记为Stage-14)。Stage-15的最后一个RDD[48]与Stage-17的最后一个RDD[49]相同。是如何做到的?我看到日志中在执行Stage-15后,将RDD[48]注册为RDD[49]。Stage-17在driver-logs中显示,但未在Executors上执行。在driver-logs中显示了任务执行,但当我查看Yarn容器的日志时,没有任何从Stage-17接收到的task证据。
支持这些观察的日志(仅driver-logs,由于后来崩溃导致我失去了executor日志)。可以看到,在Stage-17开始之前,已注册了RDD[49]:
16/06/10 22:11:22 INFO TaskSetManager: Finished task 196.0 in stage 15.0 (TID 1121) in 21 ms on slave-1 (199/200)
16/06/10 22:11:22 INFO TaskSetManager: Finished task 198.0 in stage 15.0 (TID 1123) in 20 ms on slave-1 (200/200)
16/06/10 22:11:22 INFO YarnScheduler: Removed TaskSet 15.0, whose tasks have all completed, from pool
16/06/10 22:11:22 INFO DAGScheduler: ResultStage 15 (parquet at <console>:26) finished in 0.505 s
16/06/10 22:11:22 INFO DAGScheduler: Job 9 finished: parquet at <console>:26, took 5.054011 s
16/06/10 22:11:22 INFO ParquetRelation: Using default output committer for Parquet: org.apache.parquet.hadoop.ParquetOutputCommitter
16/06/10 22:11:22 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
16/06/10 22:11:22 INFO DefaultWriterContainer: Using user defined output committer class org.apache.parquet.hadoop.ParquetOutputCommitter
16/06/10 22:11:22 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
16/06/10 22:11:22 INFO SparkContext: Starting job: parquet at <console>:26
16/06/10 22:11:22 INFO DAGScheduler: Registering RDD 49 (parquet at <console>:26)
16/06/10 22:11:22 INFO DAGScheduler: Got job 10 (parquet at <console>:26) with 25 output partitions
16/06/10 22:11:22 INFO DAGScheduler: Final stage: ResultStage 18 (parquet at <console>:26)
16/06/10 22:11:22 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 17)
16/06/10 22:11:22 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 17)
16/06/10 22:11:22 INFO DAGScheduler: Submitting ShuffleMapStage 17 (MapPartitionsRDD[49] at parquet at <console>:26), which has no missing parents
16/06/10 22:11:22 INFO MemoryStore: Block broadcast_25 stored as values in memory (estimated size 17.4 KB, free 512.3 KB)
16/06/10 22:11:22 INFO MemoryStore: Block broadcast_25_piece0 stored as bytes in memory (estimated size 8.9 KB, free 521.2 KB)
16/06/10 22:11:22 INFO BlockManagerInfo: Added broadcast_25_piece0 in memory on 172.16.20.57:44944 (size: 8.9 KB, free: 517.3 MB)
16/06/10 22:11:22 INFO SparkContext: Created broadcast 25 from broadcast at DAGScheduler.scala:1006
16/06/10 22:11:22 INFO DAGScheduler: Submitting 200 missing tasks from ShuffleMapStage 17 (MapPartitionsRDD[49] at parquet at <console>:26)
16/06/10 22:11:22 INFO YarnScheduler: Adding task set 17.0 with 200 tasks
16/06/10 22:11:23 INFO TaskSetManager: Starting task 0.0 in stage 17.0 (TID 1125, slave-1, partition 0,NODE_LOCAL, 1988 bytes)
16/06/10 22:11:23 INFO TaskSetManager: Starting task 1.0 in stage 17.0 (TID 1126, slave-2, partition 1,NODE_LOCAL, 1988 bytes)
16/06/10 22:11:23 INFO TaskSetManager: Starting task 2.0 in stage 17.0 (TID 1127, slave-1, partition 2,NODE_LOCAL, 1988 bytes)
16/06/10 22:11:23 INFO TaskSetManager: Starting task 3.0 in stage 17.0 (TID 1128, slave-2, partition 3,NODE_LOCAL, 1988 bytes)
16/06/10 22:11:23 INFO TaskSetManager: Starting task 4.0 in stage 17.0 (TID 1129, slave-1, partition 4,NODE_LOCAL, 1988 bytes)
16/06/10 22:11:23 INFO TaskSetManager: Starting task 5.0 in stage 17.0 (TID 1130, slave-2, partition 5,NODE_LOCAL, 1988 bytes)
问题
- 为什么会有两个
Jobs?将一个DAG分成两个jobs的意图是什么? Job 10的DAG看起来已经可以完成查询执行了,Job 9正在做些什么特别的吗?- 为什么
Stage-17没有被跳过?看起来创建了一些虚拟的tasks,它们有任何用处吗? 后来我尝试了另一个相对简单的查询。出乎意料地,它创建了 3 个
Jobs。sqlContext.sql("select dpHour from so order by dphour").write.parquet("/out2/")