根据我的理解,Spark中每个
但是我经常看到一个单独的操作触发了多个作业。
我试图通过对数据集进行简单的聚合来测试这一点,以获取每个类别(这里是“subject”字段)的最大值。
在检查Spark UI时,我可以看到有3个“jobs”执行
有人能帮助我理解为什么不是1而是3吗?
在检查Spark用户界面时,我发现针对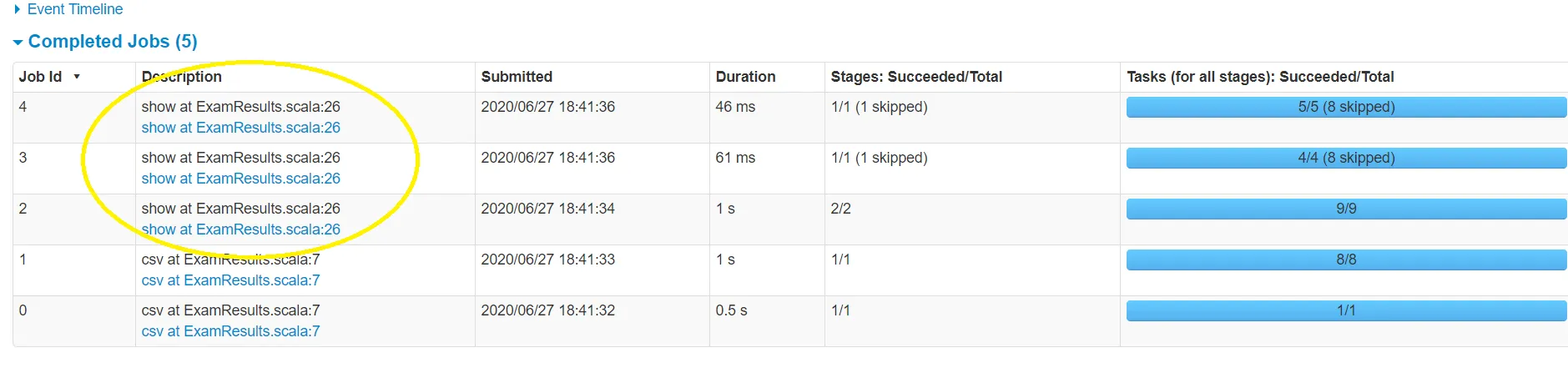
 有谁能帮助我理解为什么会出现3个而不是1个?
有谁能帮助我理解为什么会出现3个而不是1个?
action都会有一个作业。但是我经常看到一个单独的操作触发了多个作业。
我试图通过对数据集进行简单的聚合来测试这一点,以获取每个类别(这里是“subject”字段)的最大值。
在检查Spark UI时,我可以看到有3个“jobs”执行
groupBy操作,而我原本只期望有一个。有人能帮助我理解为什么不是1而是3吗?
students.show(5)
+----------+--------------+----------+----+-------+-----+-----+
|student_id|exam_center_id| subject|year|quarter|score|grade|
+----------+--------------+----------+----+-------+-----+-----+
| 1| 1| Math|2005| 1| 41| D|
| 1| 1| Spanish|2005| 1| 51| C|
| 1| 1| German|2005| 1| 39| D|
| 1| 1| Physics|2005| 1| 35| D|
| 1| 1| Biology|2005| 1| 53| C|
| 1| 1|Philosophy|2005| 1| 73| B|
// Task : Find Highest Score in each subject
val highestScores = students.groupBy("subject").max("score")
highestScores.show(10)
+----------+----------+
| subject|max(score)|
+----------+----------+
| Spanish| 98|
|Modern Art| 98|
| French| 98|
| Physics| 98|
| Geography| 98|
| History| 98|
| English| 98|
| Classics| 98|
| Math| 98|
|Philosophy| 98|
+----------+----------+
only showing top 10 rows
在检查Spark用户界面时,我发现针对
groupBy操作执行了3个“作业”,而我原本期望只有一个。
有谁能帮助我理解为什么会出现3个而不是1个?== Physical Plan ==
*(2) HashAggregate(keys=[subject#12], functions=[max(score#15)])
+- Exchange hashpartitioning(subject#12, 1)
+- *(1) HashAggregate(keys=[subject#12], functions=[partial_max(score#15)])
+- *(1) FileScan csv [subject#12,score#15] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/C:/lab/SparkLab/files/exams/students.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<subject:string,score:int>