使用Scala运行Spark作业,所有作业都按时完成,但是在作业停止之前会打印一些INFO日志,持续20-25分钟。
以下是几个UI截图,可以帮助理解问题。
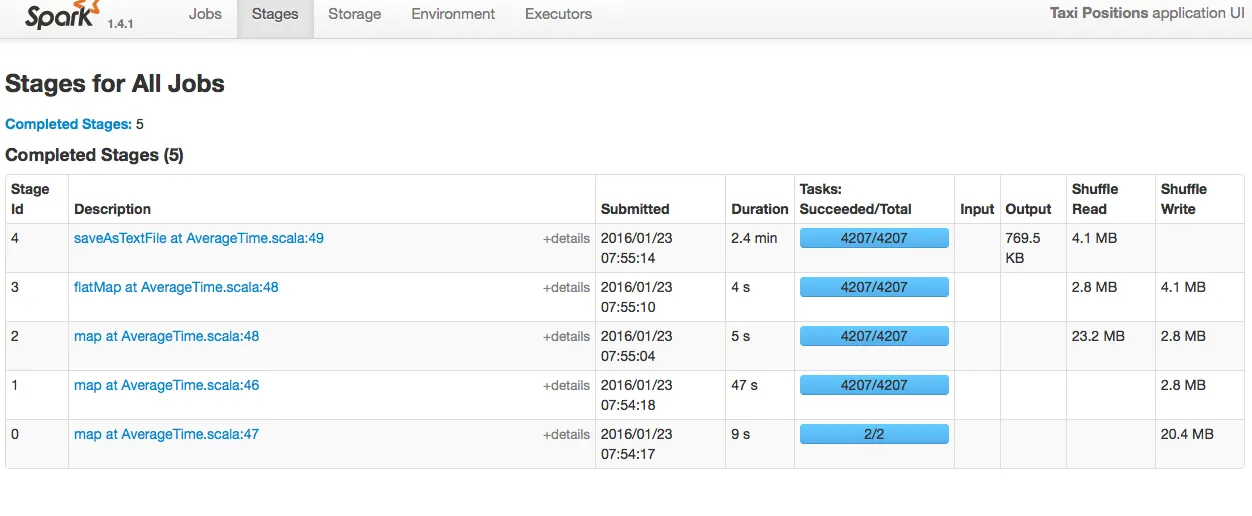
- 以下是4个阶段所需的时间:
- 以下是连续作业ID之间的时间
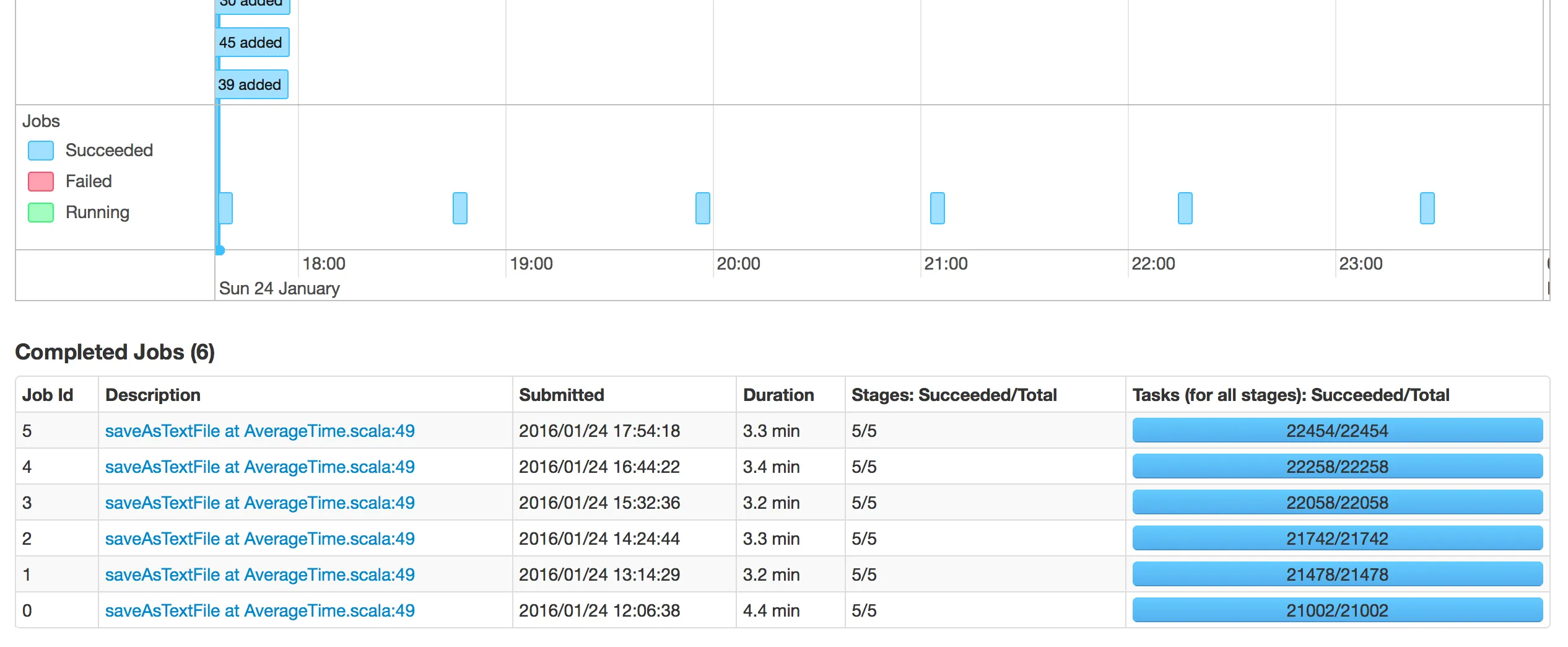
我不明白为什么在两个作业ID之间花费了这么多时间。
以下是我的代码片段:
val sc = new SparkContext(conf)
for (x <- 0 to 10) {
val zz = getFilesList(lin);
val links = zz._1
val path = zz._2
lin = zz._3
val z = sc.textFile(links.mkString(",")).map(t => t.split('\t')).filter(t => t(4) == "xx" && t(6) == "x").map(t => titan2(t)).filter(t => t.length > 35).map(t => ((t(34)), (t(35), t(5), t(32), t(33))))
val way_nodes = sc.textFile(way_source).map(t => t.split(";")).map(t => (t(0), t(1)));
val t = z.join(way_nodes).map(t => (t._2._1._2, Array(Array(t._2._1._2, t._2._1._3, t._2._1._4, t._2._1._1, t._2._2)))).reduceByKey((t, y) => t ++ y).map(t => process(t)).flatMap(t => t).combineByKey(createTimeCombiner, timeCombiner, timeMerger).map(averagingFunction).map(t => t._1 + "," + t._2)
t.saveAsTextFile(path)
}
sc.stop()