我正在阅读Saul I. Gass的《线性规划》第五版。
他给出了以下文字和示例: “给定一个n x n非奇异矩阵A,则A可以表示为乘积A=LU……如果我们让U(或L)的对角线元素都等于1,则LU分解将是唯一的……”
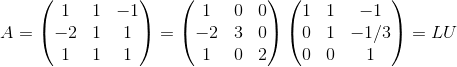
我使用了从这个SO问题中找到的代码得到可逆的下三角-上三角分解:Is there a built-in/easy LDU decomposition method in Numpy?
但我仍然不知道发生了什么,以及为什么L和U与我的教科书如此不同。有人能向我解释一下吗?
所以这段代码:
import numpy as np
import scipy.linalg as la
a = np.array([[1, 1, -1],
[-2, 1, 1],
[1, 1, 1]])
(P, L, U) = la.lu(a)
print(P)
print(L)
print(U)
D = np.diag(np.diag(U)) # D is just the diagonal of U
U /= np.diag(U)[:, None] # Normalize rows of U
print(P.dot(L.dot(D.dot(U)))) # Check
产生下列输出:
[[ 0. 1. 0.]
[ 1. 0. 0.]
[ 0. 0. 1.]]
[[ 1. 0. 0. ]
[-0.5 1. 0. ]
[-0.5 1. 1. ]]
[[-2. 1. 1. ]
[ 0. 1.5 -0.5]
[ 0. 0. 2. ]]
[[ 1. 1. -1.]
[-2. 1. 1.]
[ 1. 1. 1.]]