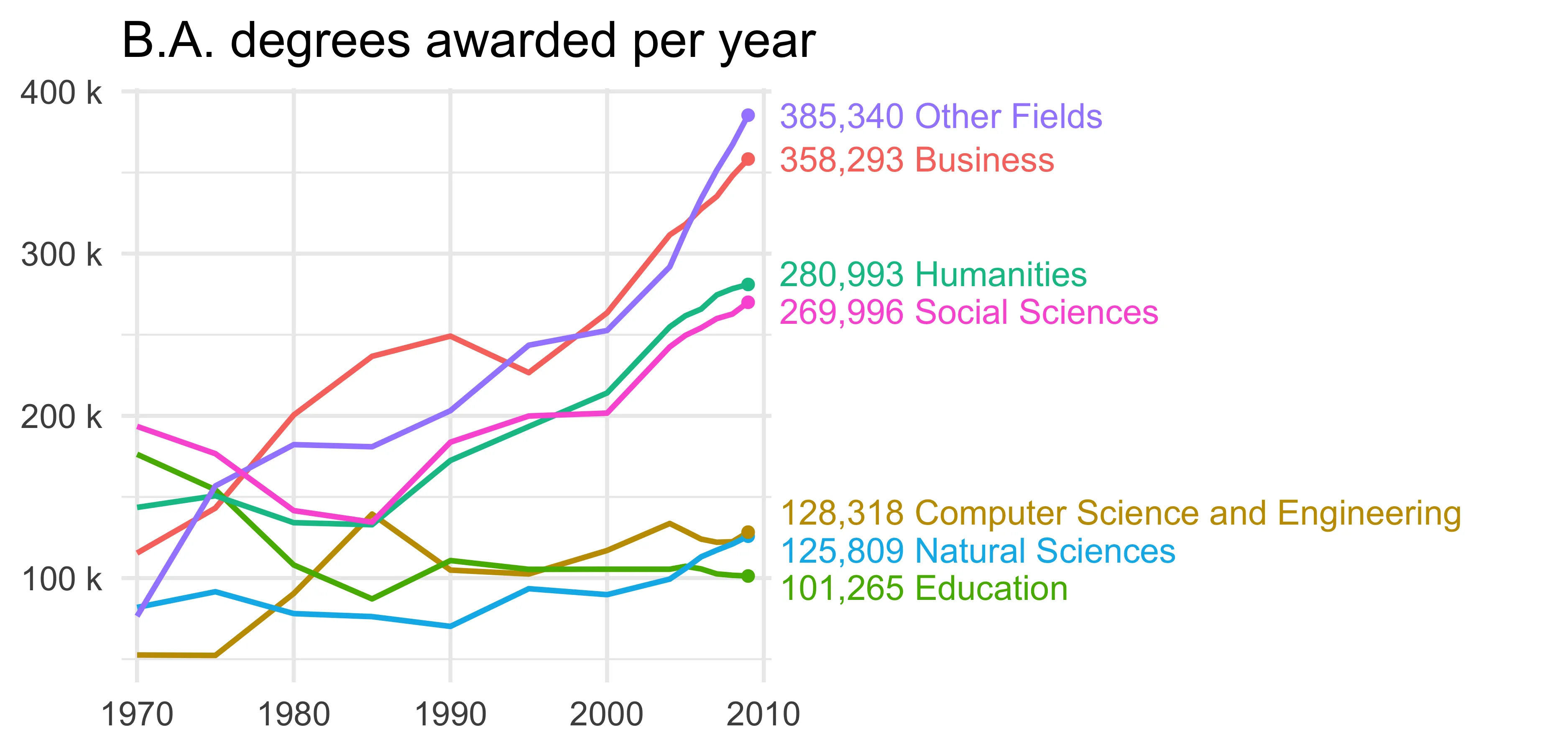
我在我的图形中遇到了重叠标签的问题。我查看了类似的问题,但没有一个能够帮助我解决问题。下面我提供了一个可重现的例子。此外,我不明白为什么direct.labels没有选择适当的颜色给每个标签。
mydf <- structure(list(ano = c(1970, 1975, 1980, 1985, 1990, 1995, 2000,
2004, 2005, 2006, 2007, 2008, 2009, 1970, 1975, 1980, 1985, 1990,
1995, 2000, 2004, 2005, 2006, 2007, 2008, 2009, 1970, 1975, 1980,
1985, 1990, 1995, 2000, 2004, 2005, 2006, 2007, 2008, 2009, 1970,
1975, 1980, 1985, 1990, 1995, 2000, 2004, 2005, 2006, 2007, 2008,
2009, 1970, 1975, 1980, 1985, 1990, 1995, 2000, 2004, 2005, 2006,
2007, 2008, 2009, 1970, 1975, 1980, 1985, 1990, 1995, 2000, 2004,
2005, 2006, 2007, 2008, 2009, 1970, 1975, 1980, 1985, 1990, 1995,
2000, 2004, 2005, 2006, 2007, 2008, 2009), field = structure(c(1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 7L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L), .Label = c("Humanites",
"Scial Sciences", "Natural Sciences", "Computer science and engineering",
"education", "business", "Other fields"), class = "factor"),
value = c(143549, 150736, 134139, 132891, 172485, 193404,
214107, 254847, 261696, 265808, 274535, 278387, 280993, 193511,
176674, 141581, 134468, 183762, 199895, 201681, 242506, 249619,
254222, 259950, 262771, 269996, 81916, 91596, 78092, 76228,
70209, 93443, 89772, 99370, 105899, 113077, 117200, 121009,
125809, 52570, 52328, 90476, 139459, 104910, 102503, 117011,
133655, 128886, 124024, 122084, 122408, 128318, 176307, 154437,
108074, 87147, 110807, 105384, 105458, 105451, 107238, 105641,
102582, 101708, 101265, 115396, 143171, 200521, 236700, 249165,
226623, 263515, 311574, 318042, 327531, 335254, 347985, 358293,
76481, 156804, 182257, 180930, 203200, 243540, 252627, 291861,
313862, 333789, 351464, 367100, 385340)), .Names = c("ano",
"field", "value"), row.names = c(NA, -91L), class = "data.frame")
require(ggplot2)
require(directlabels)
require(scales)
p <- ggplot(mydf, aes(y=value, x=ano, group=field)) + geom_line(aes(group=field, colour=field), show_guide = FALSE) +
ylab("Number of B.A. degrees awarded") + xlab("year") + theme_hyper() +
theme(legend.key = element_rect(colour = "white")) + scale_y_continuous(labels=comma)
p1 <- p + geom_dl(aes(label=field), list('last.points', cex = 1.3, hjust = 1))
p1
函数theme_hyper的定义如下:
theme_hyper <- function(angle=0, fonte="arial", size=14) {
theme(panel.grid.major = element_blank()) +
theme(panel.background = element_blank())+
theme (panel.grid.minor = element_blank()) +
theme(legend.title = element_text(family=fonte, size = size, face = "bold")) +
theme(legend.text = element_text(family=fonte, size = size, face = "bold")) +
theme(plot.title = element_text(family=fonte, size = size, face = "bold")) +
theme(axis.text.x = element_text(family=fonte, size = size, face = "bold", angle = angle, vjust = .5)) +
theme(axis.text.y= element_text(family=fonte, size = size, face = "bold", hjust=.5)) +
theme(axis.title.x= element_text(family=fonte, size = size, face = "bold")) +
theme(axis.title.y= element_text(family=fonte, size = size, face = "bold"))
}