ggplot2似乎没有内置的处理散点图上文字重叠的方法。但是,我有一个不同的情况,标签是离散轴上的标签,我想知道这里是否有比我一直在做的更好的解决方案。
一些示例代码:
library(ggplot2)
#some example data
test.data = data.frame(text = c("A full commitment's what I'm thinking of",
"History quickly crashing through your veins",
"And I take A deep breath and I get real high",
"And again, the Internet is not something that you just dump something on. It's not a big truck."),
mean = c(3.5, 3, 5, 4),
CI.lower = c(4, 3.5, 5.5, 4.5),
CI.upper = c(3, 2.5, 4.5, 3.5))
#plot
ggplot(test.data, aes_string(x = "text", y = "mean")) +
geom_point(stat="identity") +
geom_errorbar(aes(ymax = CI.upper, ymin = CI.lower), width = .1) +
scale_x_discrete(labels = test.data$text, name = "")
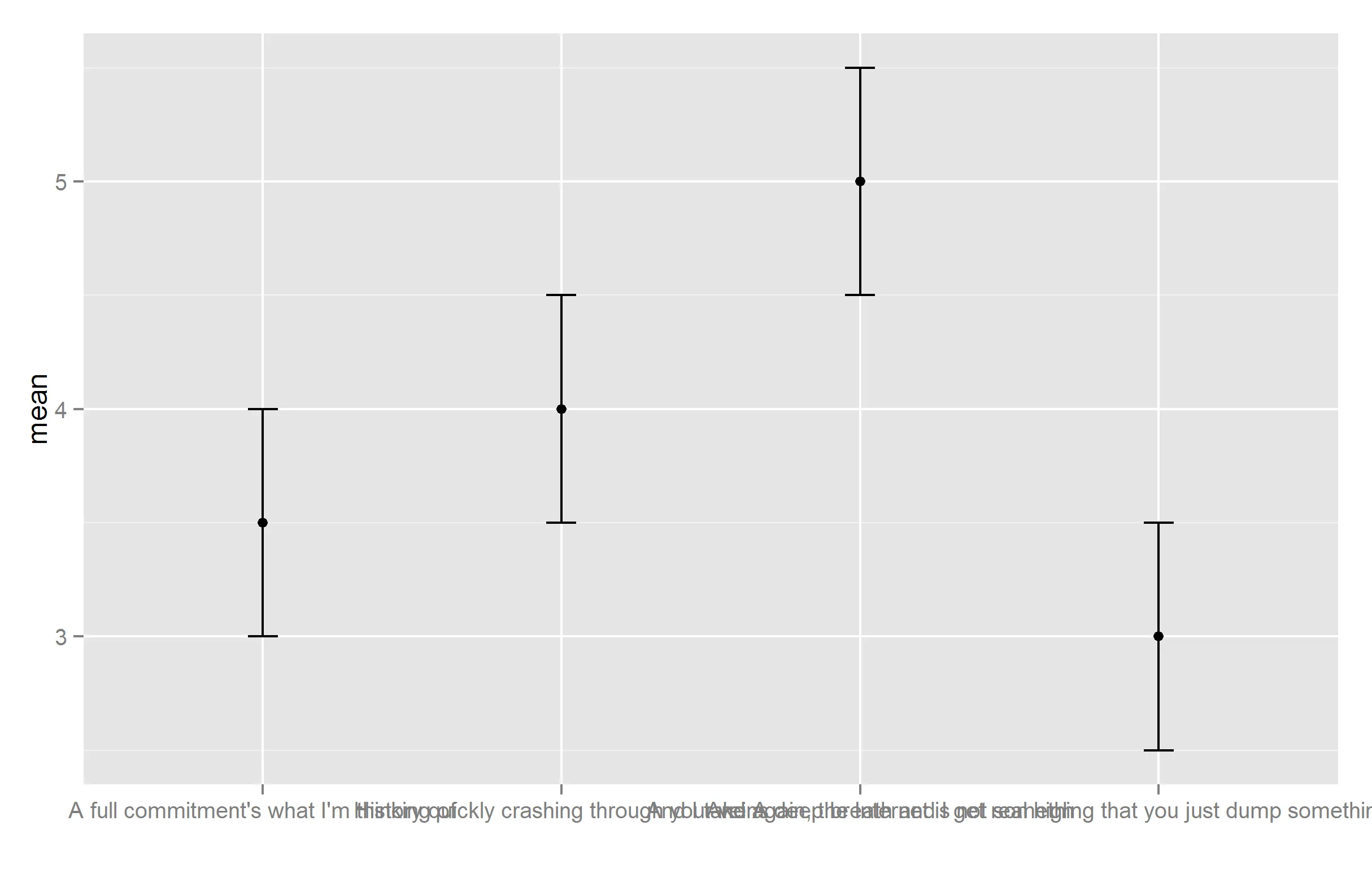
我们可以看到x轴标签是重叠的。有两种解决方案:1)缩写标签,2)在标签中添加换行符。在许多情况下,(1)就可以解决问题,但在某些情况下可能无法实现。因此,我编写了一个函数,用于将换行符(\n)添加到字符串的每n个字符,以避免名称重叠:
library(ggplot2)
#Inserts newlines into strings every N interval
new_lines_adder = function(test.string, interval){
#length of str
string.length = nchar(test.string)
#split by N char intervals
split.starts = seq(1,string.length,interval)
split.ends = c(split.starts[-1]-1,nchar(test.string))
#split it
test.string = substring(test.string, split.starts, split.ends)
#put it back together with newlines
test.string = paste0(test.string,collapse = "\n")
return(test.string)
}
#a user-level wrapper that also works on character vectors, data.frames, matrices and factors
add_newlines = function(x, interval) {
if (class(x) == "data.frame" | class(x) == "matrix" | class(x) == "factor") {
x = as.vector(x)
}
if (length(x) == 1) {
return(new_lines_adder(x, interval))
} else {
t = sapply(x, FUN = new_lines_adder, interval = interval) #apply splitter to each
names(t) = NULL #remove names
return(t)
}
}
#plot again
ggplot(test.data, aes_string(x = "text", y = "mean")) +
geom_point(stat="identity") +
geom_errorbar(aes(ymax = CI.upper, ymin = CI.lower), width = .1) +
scale_x_discrete(labels = add_newlines(test.data$text, 20), name = "")
输出结果如下:
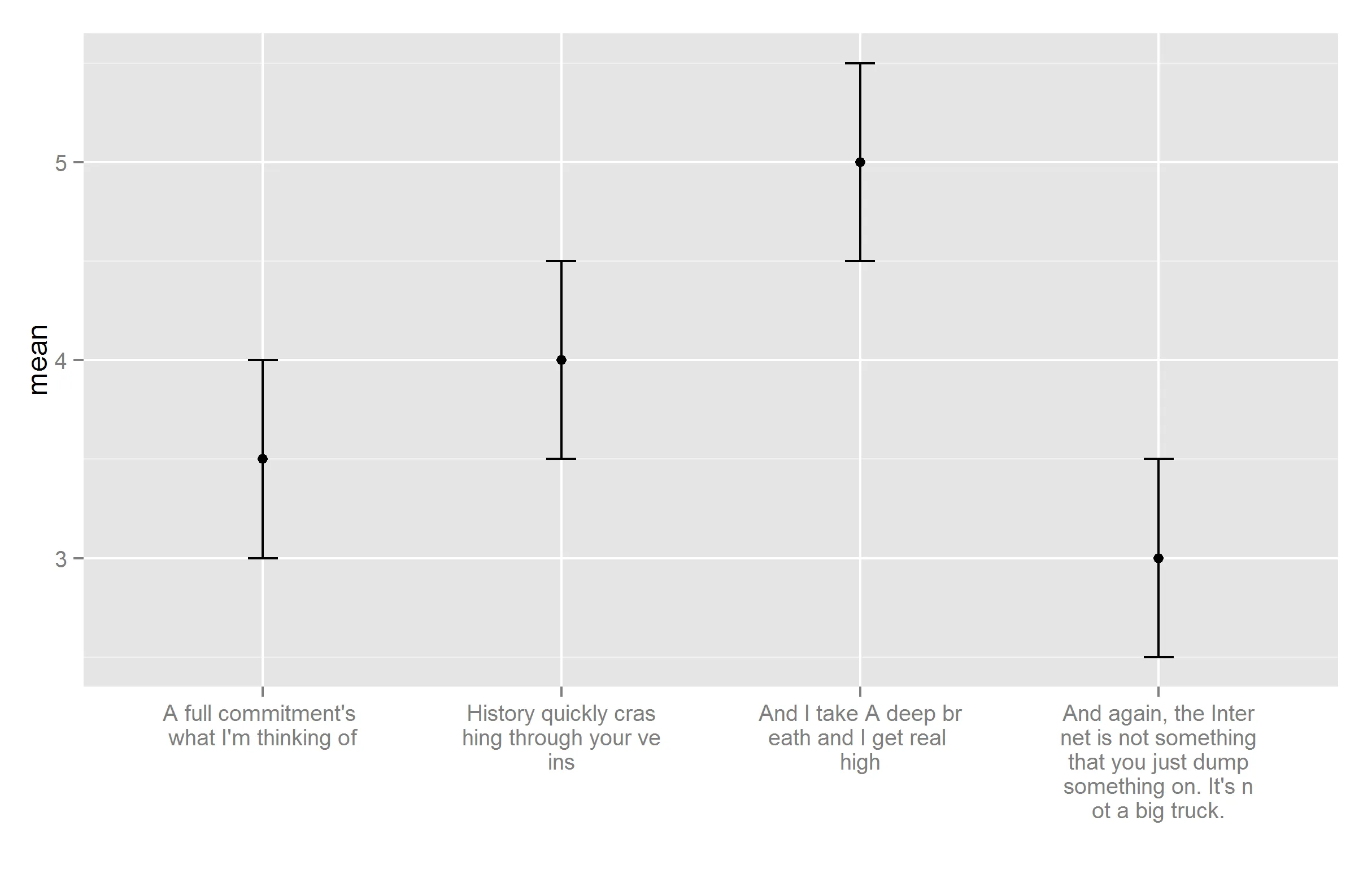
然后,您可以花一些时间调整间隔大小,以避免标签之间有太多的空白。
如果标签数量不同,则这种解决方案并不是很好,因为最佳间隔大小会改变。此外,由于正常字体不是等宽字体,标签文本也会影响宽度,因此必须特别注意选择一个好的间隔(可以通过使用等宽字体来避免这个问题,但它们的宽度更宽)。最后,new_lines_adder()函数很愚蠢,它会将单词分成两个部分,这是人类不会做的傻瓜式拆分。例如,在上面的例子中,它将“breath”拆分为“br\nreath”。可以重新编写它以避免这个问题。
您还可以减小字体大小,但这是可读性和易读性之间的权衡,通常减小字体大小是不必要的。
如何处理这种标签重叠的最佳方法是什么?
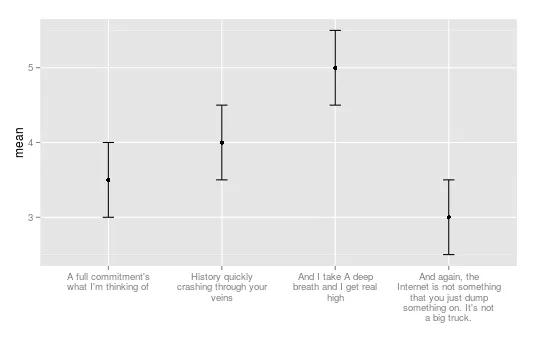
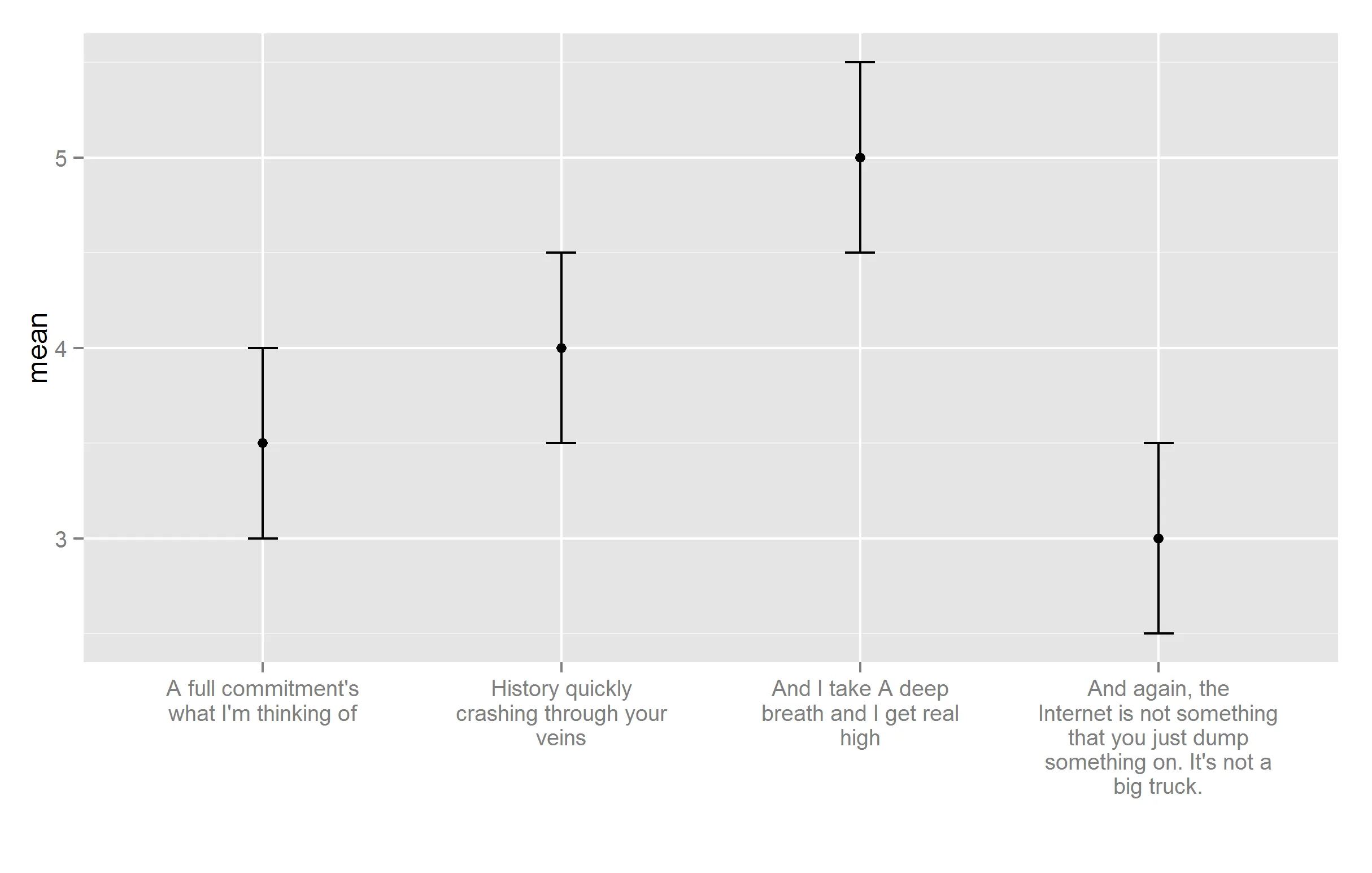
+ theme(axis.text.x = element_text(angle = 60, hjust = 1))(但如果它们非常长,这并不理想,因为它会产生大的边距)。 - scoa