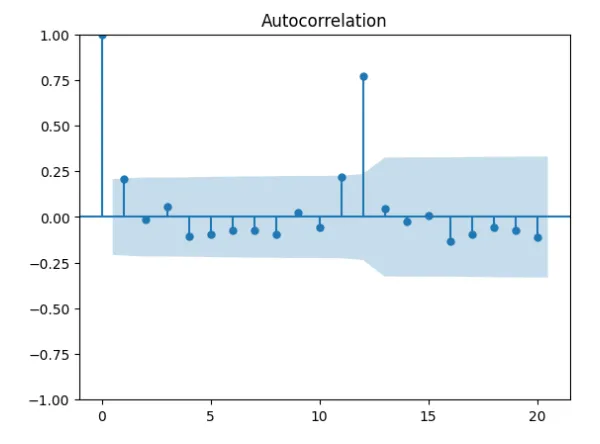
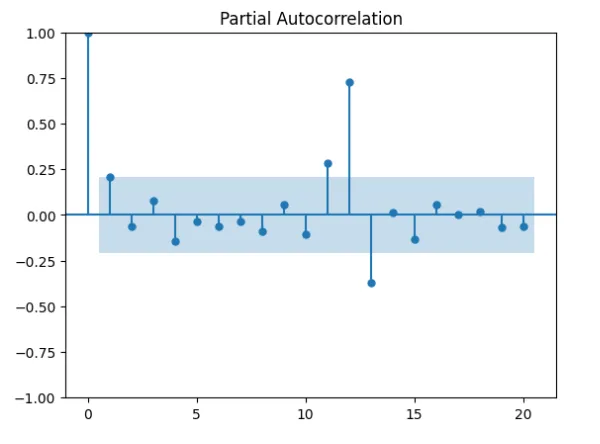
我是ARIMA的新手,正在尝试使用auto ARIMA在Python中对数据集进行建模。 我使用auto-ARIMA,因为我相信它会更好地定义p、d和q的值,但结果很差,我需要一些指导。 请查看下面我可重现的尝试:
尝试如下:
# DEPENDENCIES
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pmdarima as pm
from pmdarima.model_selection import train_test_split
from statsmodels.tsa.stattools import adfuller
from pmdarima.arima import ADFTest
from pmdarima import auto_arima
from sklearn.metrics import r2_score
# CREATE DATA
data_plot = pd.DataFrame(data removed)
# SET INDEX
data_plot['date_index'] = pd.to_datetime(data_plot['date']
data_plot.set_index('date_index', inplace=True)
# CREATE ARIMA DATASET
arima_data = data_plot[['value']]
arima_data
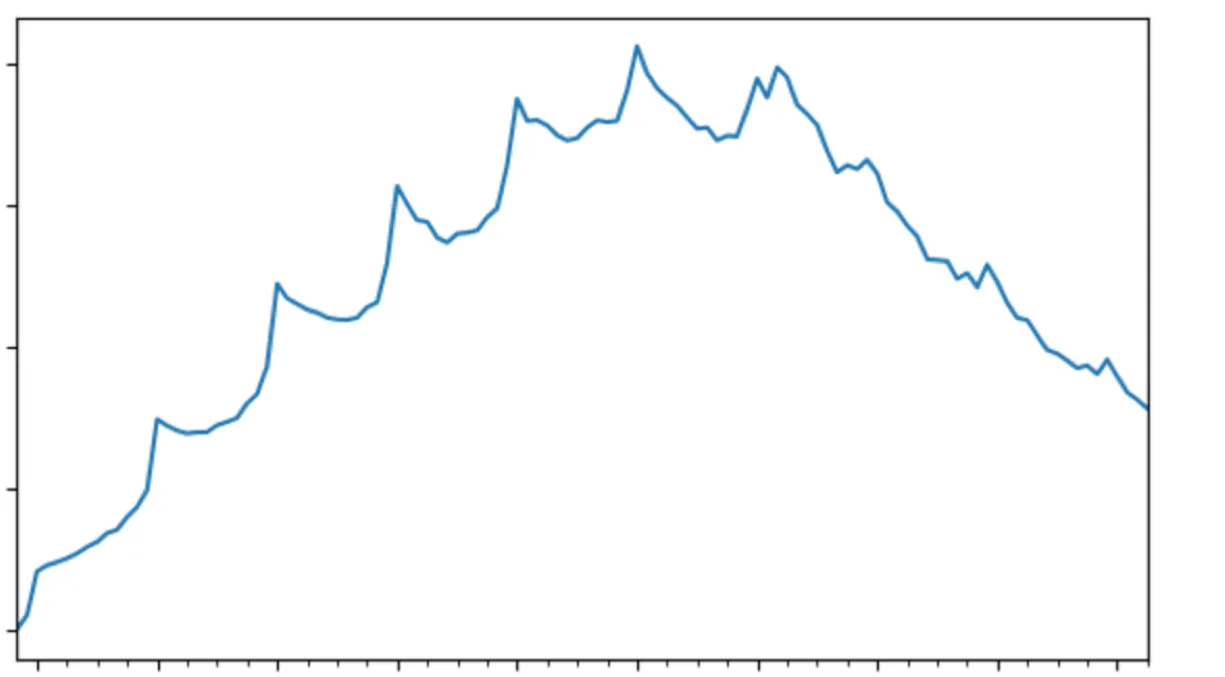
# PLOT DATA
arima_data['value'].plot(figsize=(7,4))
以上步骤会生成一个数据集,应该长这样。
# Dicky Fuller test for stationarity
adf_test = ADFTest(alpha = 0.05)
adf_test.should_diff(arima_data)
结果为0.9867,表示数据是非平稳的,需要在自动ARIMA过程中适当地进行差分处理。
# Assign training and test subsets - 80:20 split
print('Dataset dimensions;', arima_data.shape)
train_data = arima_data[:-24]
test_data = arima_data[-24:]
print('Training data dimension:', train_data.shape, round((len(train_data)/len(arima_data)*100),2),'% of dataset')
print('Test data dimension:', test_data.shape, round((len(train_data)/len(arima_data)*100),2),'% of dataset')
# Plot training & test data
plt.plot(train_data)
plt.plot(test_data)
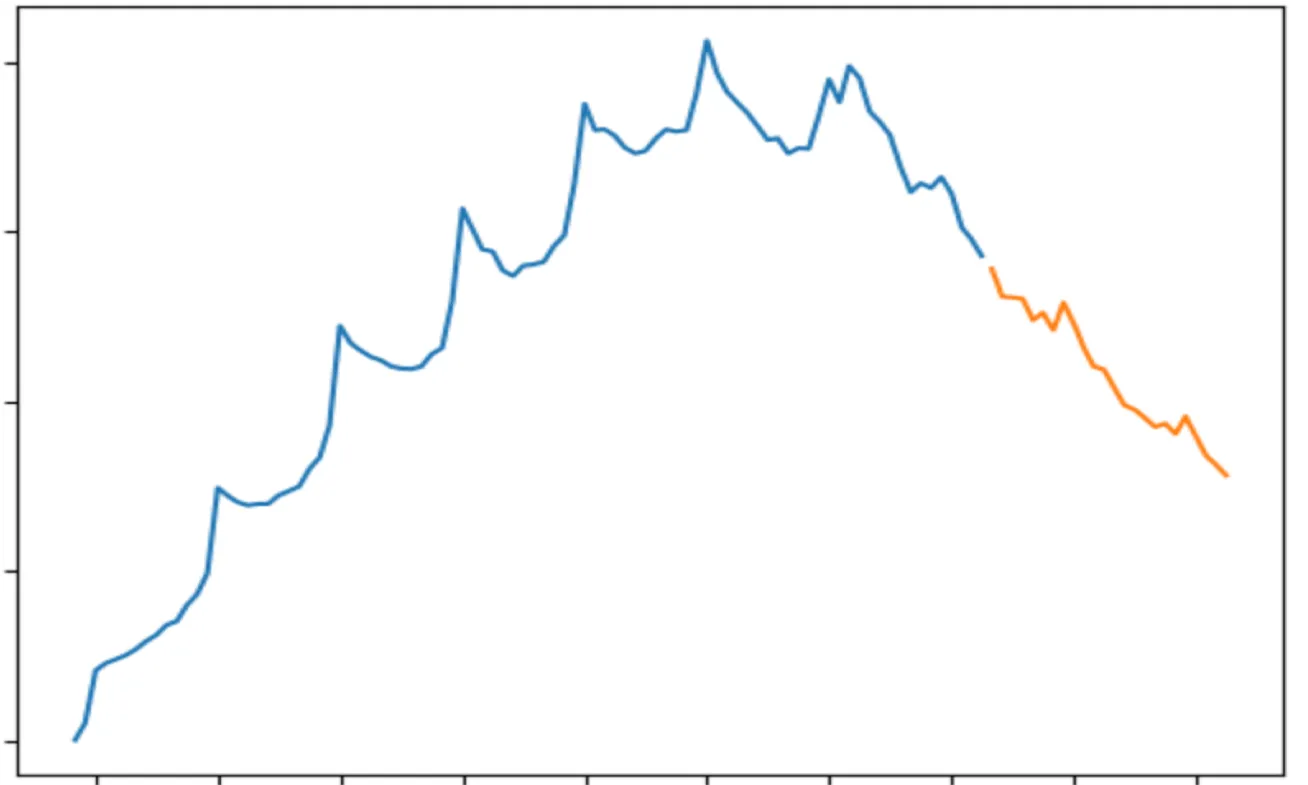
# Run auto arima
arima_model = auto_arima(train_data, start_p=0, d=1, start_q=0,
max_p=5, max_d=5, max_q=5,
start_P=0, D=1, start_Q=0, max_P=5, max_D=5,
max_Q=5, m=12, seasonal=True,
stationary=False,
error_action='warn', trace=True,
suppress_warnings=True, stepwise=True,
random_state=20, n_fits=50)
print(arima_model.aic())
模型输出表明最佳模型为 'ARIMA(1,1,1)(0,1,0)[12]',其 AIC 为 1725.35484
#Store predicted values and view resultant df
prediction = pd.DataFrame(arima_model.predict(n_periods=25), index=test_data.index)
prediction.columns = ['predicted_value']
prediction
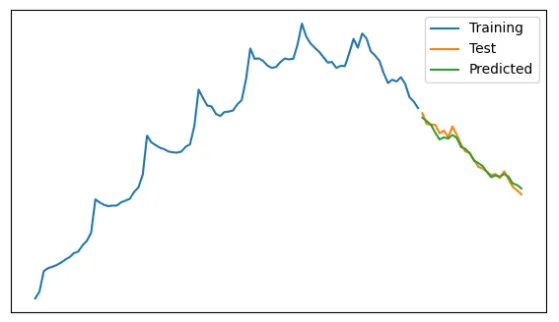
# Plot prediction against test and training trends
plt.figure(figsize=(7,4))
plt.plot(train_data, label="Training")
plt.plot(test_data, label="Test")
plt.plot(prediction, label="Predicted")
plt.legend(loc='upper right')
plt.show()
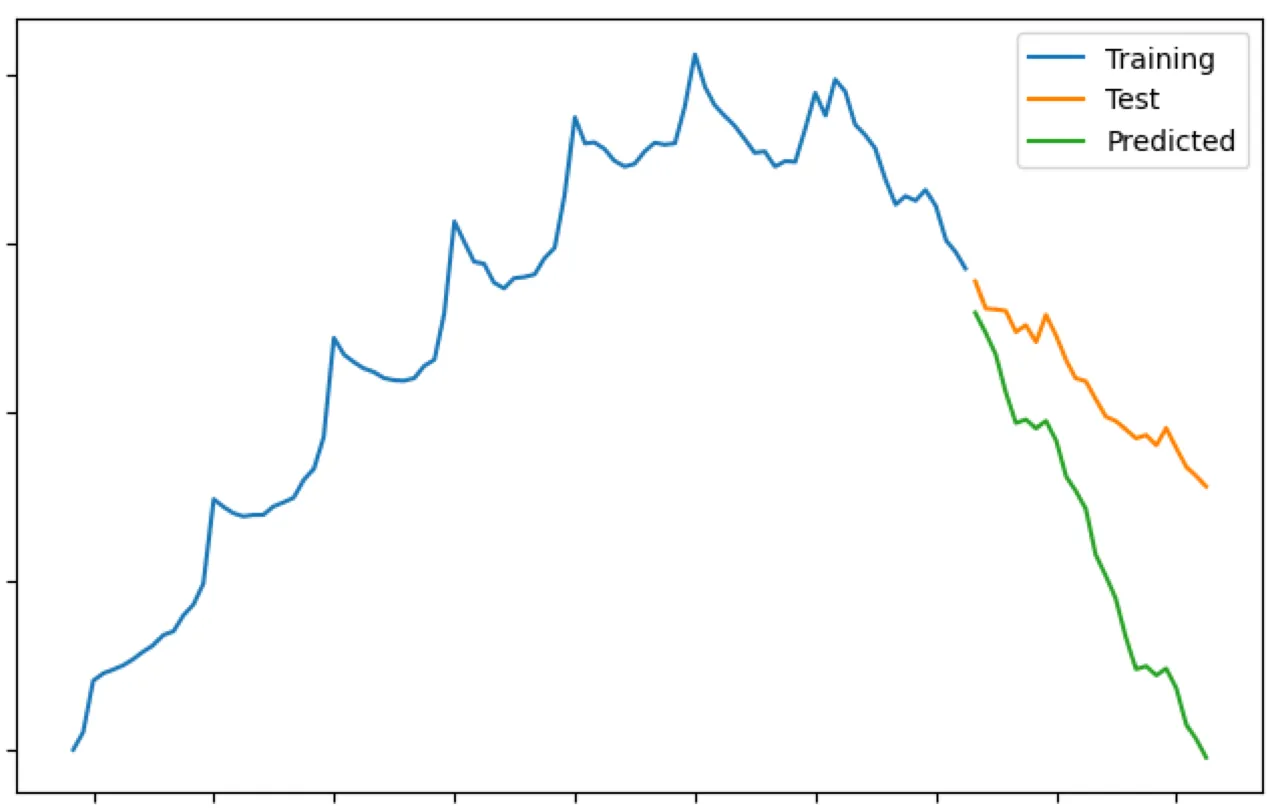
# Finding r2 model score
test_data['predicted_value'] = prediction
r2_score(test_data['value'], test_data['predicted_value'])
结果:-6.985