我有一个名为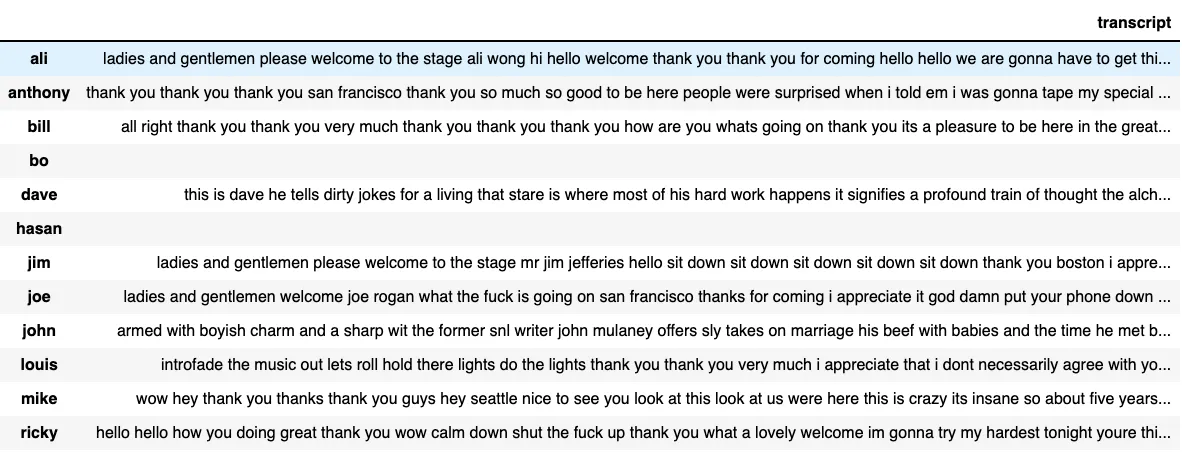 我想将其转换为Spark数据框,因此我使用createDataFrame()方法:
我想将其转换为Spark数据框,因此我使用createDataFrame()方法:
"是"
文档中说createDataFrame()可以接受pandas.DataFrame作为输入。我正在使用的Spark版本是'3.0.1'。
其他关于此问题的stackoverflow上的问题没有提到索引列消失的问题:
data_clean的pandas数据框,它长这样:
我想将其转换为Spark数据框,因此我使用createDataFrame()方法:
sparkDF = spark.createDataFrame(data_clean)
但是,这似乎会从原始数据框中删除索引列(即具有名称ali、anthony、bill等的列)。输出为:sparkDF.printSchema()
sparkDF.show()
"是"
root
|-- transcript: string (nullable = true)
+--------------------+
| transcript|
+--------------------+
|ladies and gentle...|
|thank you thank y...|
| all right thank ...|
| |
|this is dave he t...|
| |
| ladies and gen...|
| ladies and gen...|
|armed with boyish...|
|introfade the mus...|
|wow hey thank you...|
|hello hello how y...|
+--------------------+
文档中说createDataFrame()可以接受pandas.DataFrame作为输入。我正在使用的Spark版本是'3.0.1'。
其他关于此问题的stackoverflow上的问题没有提到索引列消失的问题:
- 这个有关将Pandas转换为Pyspark的问题没有提到索引列消失的问题。
- 同样,这个也没有提到。
- 而这个问题涉及数据丢失在转换过程中,但更多地与窗口函数有关。