我有以下数据:
head(df.num1)
## num_critic_for_reviews duration director_facebook_likes
## 1 723 178 0
## 2 302 169 563
## 3 602 148 0
## 4 813 164 22000
## 5 388 100 131
## 6 462 132 475
## actor_3_facebook_likes actor_1_facebook_likes gross num_voted_users
## 1 855 1000 760505847 886204
## 2 1000 40000 309404152 471220
## 3 161 11000 200074175 275868
## 4 23000 27000 448130642 1144337
## 5 365 131 46975183 8
## 6 530 640 73058679 212204
## cast_total_facebook_likes facenumber_in_poster num_user_for_reviews
## 1 4834 0 3054
## 2 48350 0 1238
## 3 11700 1 994
## 4 106759 0 2701
## 5 143 0 450
## 6 1873 1 738
## budget title_year actor_2_facebook_likes imdb_score aspect_ratio
## 1 2.4e+08 2009 936 7.9 1.8
## 2 3.0e+08 2007 5000 7.1 2.4
## 3 2.4e+08 2015 393 6.8 2.4
## 4 2.5e+08 2012 23000 8.5 2.4
## 5 1.0e+07 2015 12 7.1 2.4
## 6 2.6e+08 2012 632 6.6 2.4
## movie_facebook_likes
## 1 33000
## 2 0
## 3 85000
## 4 164000
## 5 0
## 6 24000
然后我按以下方式运行kmeans:
set.seed(111)
km_out <- kmeans(df.num1,centers=3) #perform kmeans cluster with k=3
我们现在计算物体与聚类中心之间的距离,以确定异常值,并识别出5个最大的距离作为异常值(任意标识)。
centers <- km_out$centers[km_out$cluster, ] # "centers" is a data frame of 3 centers but the length of dataset so we can calculate distance difference easily.
distances <- sqrt(rowSums((df.num1 - centers)^2))
(outliers <- order(distances, decreasing=T)[1:5])# these rows are 5 top outliers
## [1] 3860 3006 2324 2335 3424
让我们获取附加了距离的数据框:
df.num1$distance<-distances
df.num1$cluster<-km_out$cluster
打印有关异常值的详细信息(最大的五个距离值)
(df.num1[outliers,])
## num_critic_for_reviews duration director_facebook_likes
## 3860 202 112 0
## 3006 73 134 45
## 2324 174 134 6000
## 2335 105 103 78
## 3424 150 124 78
## actor_3_facebook_likes actor_1_facebook_likes gross num_voted_users
## 3860 38 717 211667 53508
## 3006 0 9 195888 5603
## 2324 745 893 2298191 221552
## 2335 101 488 410388 13727
## 3424 4 6 439162 106160
## cast_total_facebook_likes facenumber_in_poster num_user_for_reviews
## 3860 907 0 131
## 3006 11 0 45
## 2324 2710 0 570
## 2335 991 1 79
## 3424 28 0 430
## budget title_year actor_2_facebook_likes imdb_score aspect_ratio
## 3860 4.2e+09 2005 126 7.7 2.4
## 3006 2.5e+09 2005 2 7.1 2.4
## 2324 2.4e+09 1997 851 8.4 1.8
## 2335 2.1e+09 2004 336 6.9 1.8
## 3424 1.1e+09 1988 5 8.1 1.8
## movie_facebook_likes distance cluster
## 3860 4000 4.1e+09 2
## 3006 607 2.4e+09 2
## 2324 11000 2.3e+09 2
## 2335 973 2.0e+09 2
## 3424 0 9.8e+08 2
但这些只是基于距离聚类中心最远的数据点......
我希望的是一些基于统计量的方法,例如基于z得分的极值(比如定义为离群值的> 2个标准差),而不仅仅是取几个最大距离值的观测值(行)......
最终输出的想法可能包括:
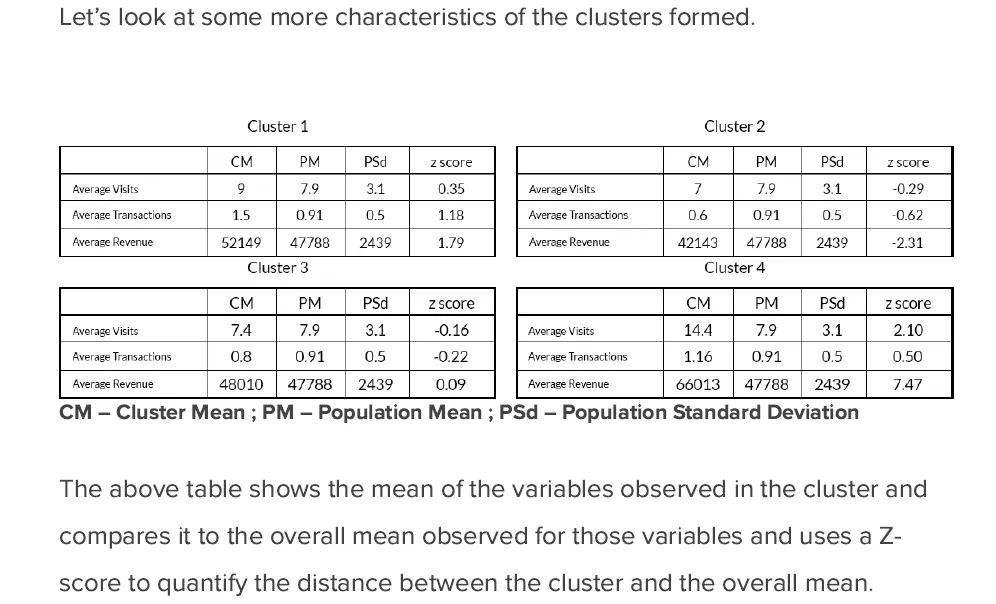

我希望能够得到一些帮助/指引,以获得如上所示的结果......
谢谢!