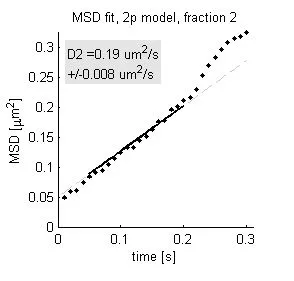
我想对几个数据点进行线性拟合,如图所示。由于我知道截距(在这种情况下为0.05),因此我只想拟合具有特定截距的线性区域中的点。在这种情况下,它将是5:22的点(但不包括22:30)。
我正在寻找简单的算法来确定这些最佳点的数量,基于...嗯,问题就在这里... R ^ 2?有任何想法吗?
我考虑使用点1到2:30、2到3:30等来探测拟合的R ^ 2,但我真的不知道如何将其编写成清晰简单的函数。对于具有固定截距的拟合,我使用polyfit0 (http://www.mathworks.com/matlabcentral/fileexchange/272-polyfit0-m)。谢谢任何建议!
编辑: 样本数据:
编辑: 样本数据:
intercept = 0.043;
x = 0.01:0.01:0.3;
y = [0.0530642513911393,0.0600786706929529,0.0673485248329648,0.0794662409166333,0.0895915873196170,0.103837395346484,0.107224784565365,0.120300492775786,0.126318699218730,0.141508831492330,0.147135757370947,0.161734674733680,0.170982455701681,0.191799936622712,0.192312642057298,0.204771365716483,0.222689541632988,0.242582251060963,0.252582727297656,0.267390860166283,0.282890010610515,0.292381165948577,0.307990544720676,0.314264952297699,0.332344368808024,0.355781519885611,0.373277721489254,0.387722683944356,0.413648156978284,0.446500064130389;];