我刚看到其中一个内核,不明白这段代码(Kaggle中的房屋预测数据集)第三个管道中的
Numpy文档中说:
- 返回:
- 一个数组,其元素为x + 1的自然对数值
- 其中x属于输入数组的所有元素。
在查找原始和转换后的相同特征数组的偏斜度时,找到带有添加的对数的目的是什么?它实际上是做什么的?
numpy.log1p()是做什么的。Numpy文档中说:
- 返回:
- 一个数组,其元素为x + 1的自然对数值
- 其中x属于输入数组的所有元素。
在查找原始和转换后的相同特征数组的偏斜度时,找到带有添加的对数的目的是什么?它实际上是做什么的?
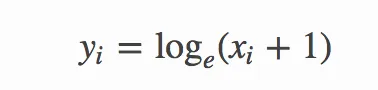
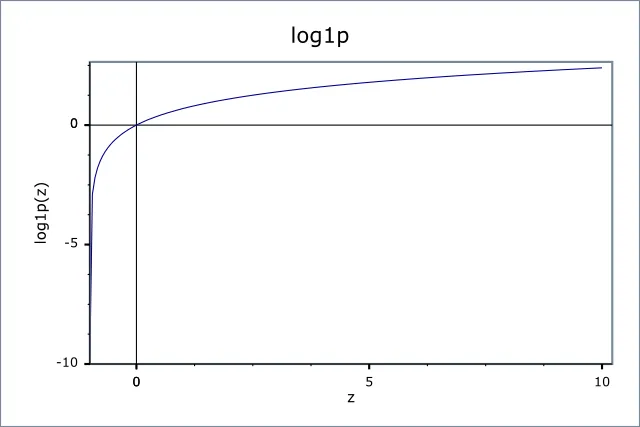
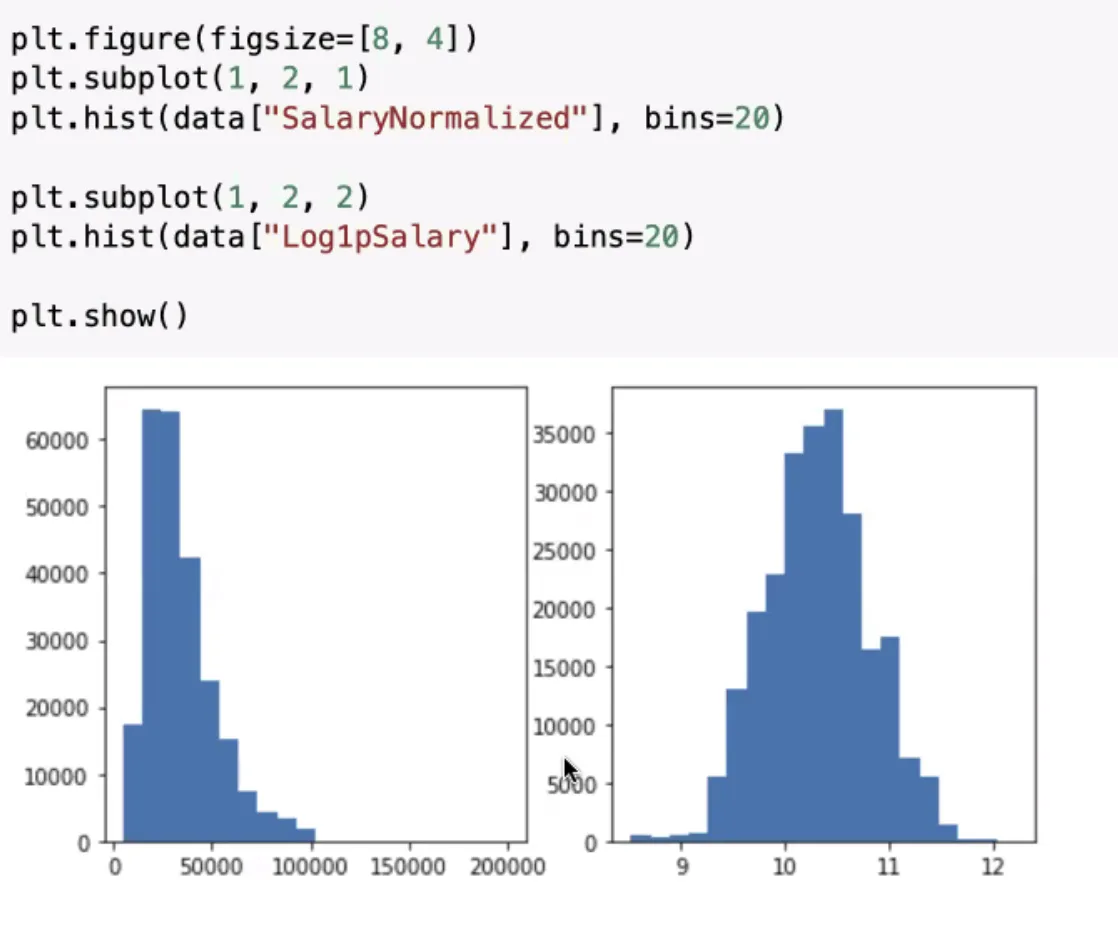
feat_trial中有数据。顺便问一下,取log的意义是什么? - Sabah