TL;DR:
set()函数使用Python迭代协议创建一个集合。但是,在Python级别上遍历NumPy数组非常慢,因此在进行迭代之前,使用
tolist()将数组转换为Python列表会更快。
要理解为什么遍历NumPy数组很慢,重要的是要知道Python对象、Python列表和NumPy数组在内存中的存储方式。
Python对象需要一些簿记属性(如引用计数、链接到其类的指针等)以及它所表示的值。例如,整数
ten = 10可能看起来像这样:
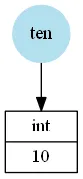
蓝色圆圈代表在Python解释器中用于变量
ten的“名称”,而下方的对象(实例)实际上表示整数(由于此处不重要,因此我在图像中忽略了它们的记录属性)。
Python的
list只是Python对象的集合,例如
mylist = [1, 2, 3]将被保存如下:
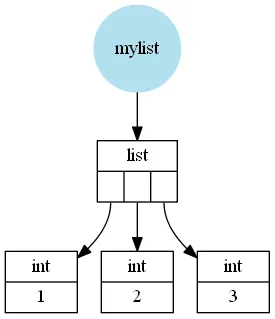
这次列表引用了Python整数
1,
2和
3以及名称
mylist只是引用
list实例。
但是一个数组myarray = np.array([1, 2, 3])不会将Python对象存储为元素:
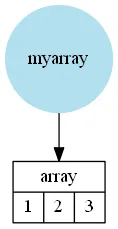
NumPy的
array实例直接存储值
1、
2和
3。
使用这些信息,我可以解释为什么迭代数组比迭代列表要慢得多:
每次访问列表中的下一个元素时,列表只返回一个存储的对象。这非常快,因为元素已经存在作为Python对象(它只需要将引用计数增加一)。
另一方面,当您想要一个数组元素时,它需要创建一个新的Python“盒子”来存储值以及所有簿记信息,然后才能返回。当您遍历数组时,它需要为数组中的每个元素创建一个Python盒子。
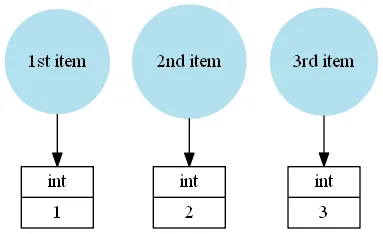
创建这些盒子很慢,这也是为什么迭代NumPy数组比迭代Python集合(列表/元组/集合/字典)慢得多的主要原因,因为它们存储值
及其盒子。
import numpy as np
arr = np.arange(100000)
lst = list(range(100000))
def iterateover(obj):
for item in obj:
pass
%timeit iterateover(arr)
%timeit iterateover(lst)
set 的“构造函数”只是对对象进行迭代。
有一件事情我无法确定,那就是为什么 tolist 方法更快。最终,结果 Python 列表中的每个值都需要在“Python 盒子”中,因此 tolist 无法避免太多工作。但其中一件确定的事情是,list(array) 比 array.tolist() 更慢:
arr = np.arange(100000)
%timeit list(arr)
# 20 ms ± 114 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit arr.tolist()
每个操作的时间复杂度都是O(n),但常数因子不同。
在您的情况下,您将set()与tolist()进行了比较,这并不是一个特别好的比较。将set(arr)与list(arr)或set(arr.tolist())与arr.tolist()进行比较会更有意义。
arr = np.random.randint(0, 1000, (10000, 3))
def tosets(arr):
for line in arr:
set(line)
def tolists(arr):
for line in arr:
list(line)
def tolists_method(arr):
for line in arr:
line.tolist()
def tosets_intermediatelist(arr):
for line in arr:
set(line.tolist())
%timeit tosets(arr)
%timeit tolists(arr)
%timeit tolists_method(arr)
%timeit tosets_intermediatelist(arr)
如果你想要
set,最好使用
set(arr.tolist())。对于更大的数组,使用
np.unique可能会更有意义,但由于你的行只包含3个项目,所以这可能会更慢(对于数千个元素,它可能会快得多!)。
在评论中,您询问了有关numba的问题,是的,numba可以加速此过程。
Numba支持类型化集合(仅数字类型),但这并不意味着它总是更快。
我不确定numba如何重新实现集合,但由于它们是类型化的,很可能也避免了“Python盒子”,并直接将值存储在集合内部:
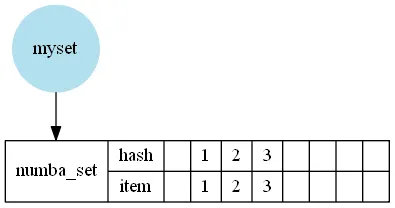
由于涉及到哈希和空槽(Python 在集合中使用开放地址法),因此集合比列表更加复杂。
与 NumPy 的 array 类似,numba 的 set 直接保存值。因此,当您将 NumPy 的 array 转换为 numba 的 set(或反之亦然)时,它根本不需要使用“Python boxes”,因此在 numba 的 nopython 函数中创建 set 会比 set(arr.tolist()) 操作快得多:
import numba as nb
@nb.njit
def tosets_numba(arr):
for lineno in range(arr.shape[0]):
set(arr[lineno])
tosets_numba(arr)
%timeit tosets_numba(arr)
这比使用
set(arr.tolist())方法快大约五倍。但需要强调的是,我没有从函数中返回
set。当您从Numba nopython函数返回一个
set到Python时,Numba会创建一个Python set——包括为集合中所有值“创建盒子”(这是Numba隐藏的内容)。
顺便说一下:如果您将list传递给Numba nopython函数或从这些函数返回列表,则会发生相同的装箱/拆箱操作。因此,在Numba中,Python中的O(1)操作变成了O(n)操作!这就是为什么通常最好将NumPy数组传递给numba nopython函数(这是O(1))。
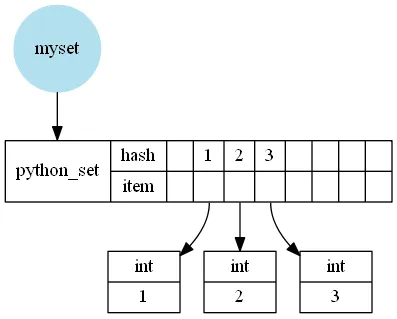
我假设如果你从函数中
返回这些集合(现在不太可能,因为numba目前不支持列表),这将会更慢(因为它创建了一个numba集合,并稍后将其转换为python集合),或者只是稍微快一点(如果numbaset -> pythonset的转换速度真的非常快)。
个人而言,我仅会在以下条件下使用numba来处理集合:不需要从函数中返回集合且所有操作都在函数内部进行,并且集合上的所有操作都支持nopython模式。在其他任何情况下,我都不会在此处使用numba。
注意:应避免使用
from numpy import *,因为这样会隐藏一些Python内置函数(例如
sum、
min、
max等),并将大量内容放入全局变量中。最好使用
import numpy as np。在函数调用前加上
np.可以使代码更清晰,而且打字量也不多。
set需要进行一些哈希和计算,以确定在集合中插入新元素的位置。转换为list可能只是一个简单的复制。 - Jean-François Fabrex是什么形状?数据类型是什么?我看到了3个和4个元素的子列表。但是,是的,set是一个类似于字典(只有键没有值)的Python对象。tolist是一个编译numpy方法。 - hpaulj