我的问题
我正在尝试适配一个(机器学习)模型,该模型接收音频文件(.wav)并从中预测情感(多标签分类)。
我正在尝试从文件中读取采样率和信号,但是当调用 scipy.io.wavfile 中的 read(filename) 时,我得到了 ValueError:不完整的wav块。
我尝试过的
我尝试从
scipy.read()切换到librosa.read()。
它们都输出信号和采样率,但由于某种原因librosa所需的时间是scipy的指数倍,对我的任务来说不实用。我尝试了建议here的
sr,y = scipi.io.wavfile.read(open(filename, 'r')),但没有成功。我尝试查看我的文件并检查可能导致问题的原因:
在所有2084个wav文件中,有1057个是好的(=scipy能够读取它们),而1027个是坏的(=引发了错误)。
我似乎找不到任何指向文件通过或失败的原因,但无论如何,这是一个奇怪的结果,因为所有文件都来自同一origin数据集。我听说人们说我可以使用一些软件将文件重新导出为wav,并且应该可以解决问题。
我没有尝试这个方法,因为a)我没有任何音频处理软件,而且它似乎过度kill, b)我想理解实际问题而不是贴上创可贴。
最小、可重复的示例
假设 filenames 是我的所有音频文件的子集,其中包含 fn_good 和 fn_bad ,其中 fn_good 是一个被处理的实际文件,而 fn_bad 是一个会引发错误的实际文件。
def extract_features(filenames):
for fn in filenames:
sr, y = scipy.io.wavfile.read(fn)
print('Signal is: ', y)
print('Sample rate is: ', sr)
附加信息
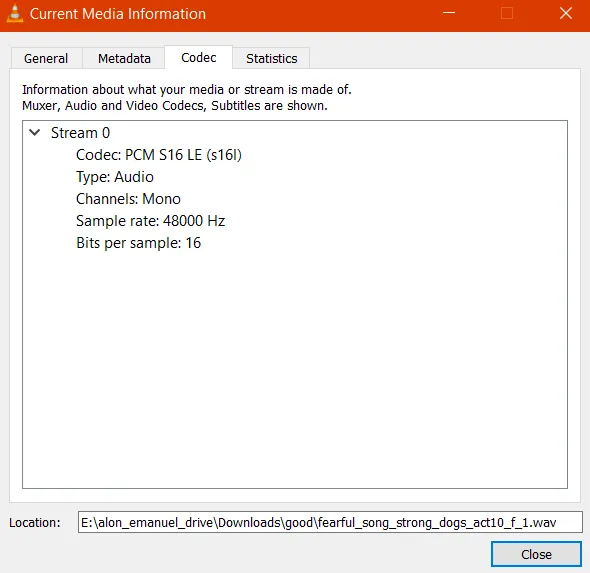
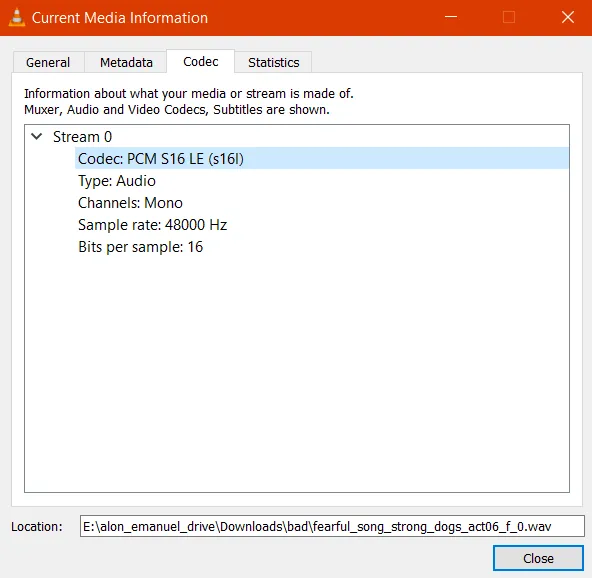
使用VLC时,似乎scipy.io.wavfile支持编解码器,但两个文件都有相同的编解码器,所以它们没有产生相同的效果是很奇怪的...
好的文件的编解码器:
坏的文件的编解码器:

wavio,它似乎运行得很好。 (我仍然想知道为什么scipy会这样做,所以不接受此答案...) - Alon Emanuel