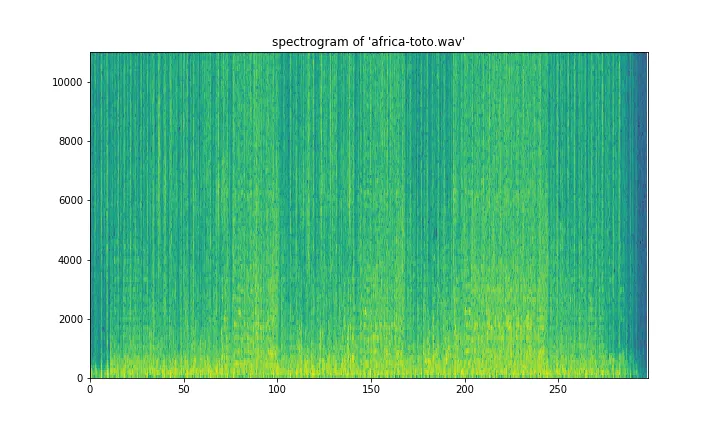
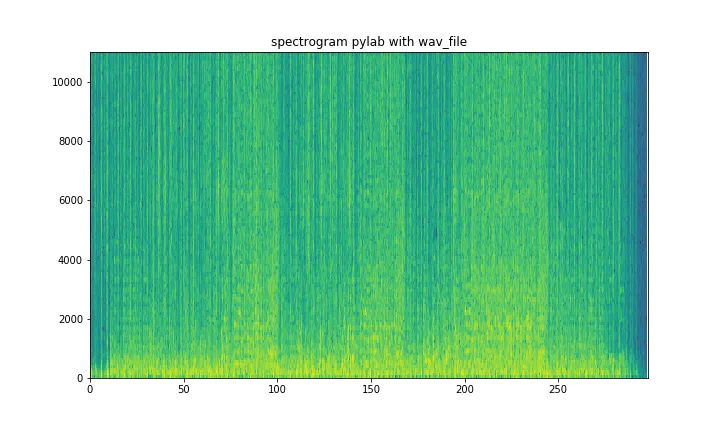
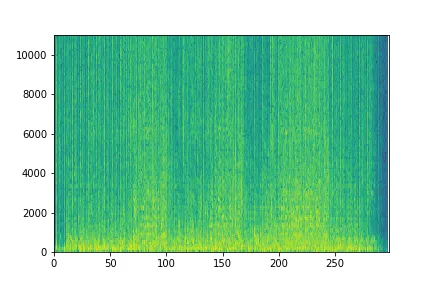
我正在尝试使用scipy文件夹在Python中加载.wav文件。我的最终目标是创建该音频文件的声谱图。读取文件的代码可以概括如下:
import scipy.io.wavfile as wav
(sig, rate) = wav.read(_wav_file_)
对于一些 .wav 文件,我收到以下错误:
WavFileWarning: 块(非数据)未被理解,跳过它。 WavFileWarning) ** ValueError:不完整的 wav 块。
因此,我决定使用 librosa 来读取这些文件,使用以下代码:
import librosa
(sig, rate) = librosa.load(_wav_file_, sr=None)
这在所有情况下都可以正常工作,但我注意到频谱图的颜色有所不同。虽然它是完全相同的图像,但颜色却被反转了。更具体地说,我注意到当保持相同的规格计算函数,只改变读取
.wav的方式时,就会出现这种差异。有什么想法可以解释这个问题吗?两种方法读取.wav文件之间是否存在默认差异?(rate1, sig1) = wav.read(spec_file) # rate1 = 16000
sig, rate = librosa.load(spec_file) # rate 22050
sig = np.array(α*sig, dtype = "int16")
有一个几乎有效的方法是将sig的结果与常量α相乘,这个alpha是从scipy wavread和librosa导出的信号的最大值之间的比例尺。然而,两个信号的速率仍然不同。