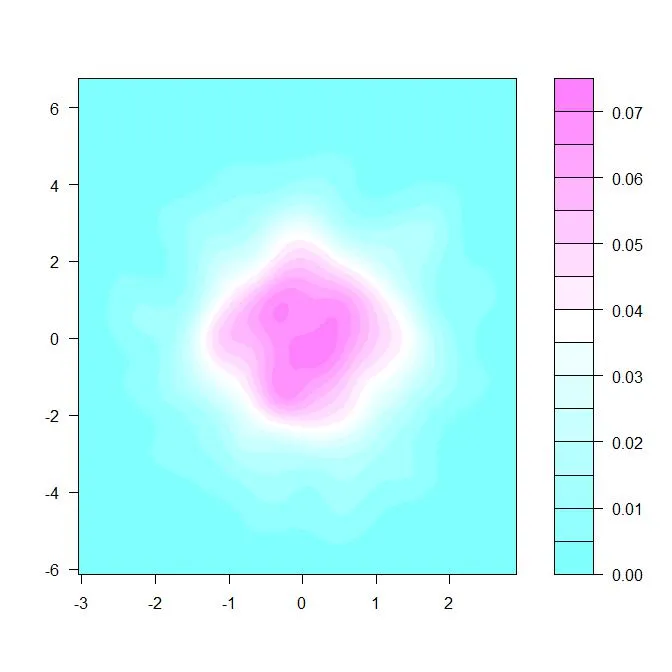
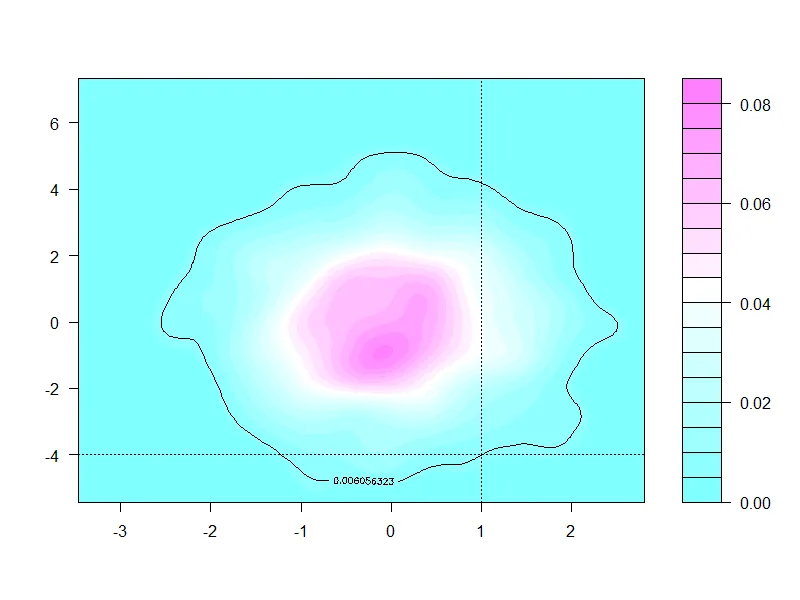
如果您指定了一个区域,那么该区域相对于您的密度函数就有一个概率。当然,单个点的概率为零,但是在该点上确实具有非零密度。那么这是什么呢?
密度是该概率密度在该区域上积分后除以标准区域测量值,并将标准区域测量值趋近于零的极限。所有这些都是基本微积分,通过编写一种计算该密度在该区域上积分的例程也相当容易,尽管我想 MASS 通常使用更复杂的积分技术。以下是基于您的示例快速编写的例程:
library(MASS)
n <- 100
a <- rnorm(1000)
b <- rnorm(1000, sd=2)
f1 <- kde2d(a, b, n = 100)
lims <- c(min(a),max(a),min(b),max(b))
filled.contour(f1)
prob <- function(f,xmin,xmax,ymin,ymax,n,lims){
ixmin <- max( 1, n*(xmin-lims[1])/(lims[2]-lims[1]) )
ixmax <- min( n, n*(xmax-lims[1])/(lims[2]-lims[1]) )
iymin <- max( 1, n*(ymin-lims[3])/(lims[4]-lims[3]) )
iymax <- min( n, n*(ymax-lims[3])/(lims[4]-lims[3]) )
avg <- mean(f$z[ixmin:ixmax,iymin:iymax])
probval <- (xmax-xmin)*(ymax-ymin)*avg
return(probval)
}
prob(f1,0.5,1.5,-4.5,-3.5,n,lims)
prob(f1,-1,1,-1,1,n,lims)
prob(f1,-2,2,-2,2,n,lims)
prob(f1,0,1,-1,1,n,lims)
prob(f1,1,2,-1,1,n,lims)
prob(f1,-3,3,-3,3,n,lims)
lims
注意,这个程序看起来没问题,并且给出了合理的答案,但是它还没有经过我在生产环境下进行的严格审查。