有一段时间了,我注意到TensorFlow(v0.8)似乎没有充分利用我Titan X的计算能力。对于我运行的几个CNN,GPU使用率似乎没有超过30%。通常,GPU利用率甚至更低,只有15%左右。表现出这种行为的CNN之一是来自DeepMind的Atari论文中使用Q-learning的CNN(请参见下面代码的链接)。当我看到我们实验室中其他人运行使用Theano或Torch编写的CNN时,GPU使用率通常为80% +。这使我想知道,为什么我在TensorFlow中编写的CNN如此“慢”,我可以做些什么来更有效地利用GPU处理能力?总的来说,我对分析GPU操作并发现瓶颈所在的方法很感兴趣。如果有任何建议,请告诉我,因为目前似乎不太可能通过TensorFlow进行此操作。
我为了找出问题原因而做的事情:
我为了找出问题原因而做的事情:
- 分析TensorFlow的设备放置,一切都在gpu:/0上,看起来没问题。
- 使用cProfile优化了批量生成和其他预处理步骤。预处理在单线程上执行,但由TensorFlow执行的实际优化需要更长时间(请参见下面的平均运行时间)。一个明显的加快速度的想法是使用TF的队列运行程序,但由于批处理准备已经比优化快20倍,我想知道这是否会带来很大的差异。
Avg. Time Batch Preparation: 0.001 seconds
Avg. Time Train Operation: 0.021 seconds
Avg. Time Total per Batch: 0.022 seconds (45.18 batches/second)
在多台机器上运行以排除硬件问题。
升级到最新版本的CuDNN v5(RC)、CUDA Toolkit 7.5并在一周前从源代码重新安装了TensorFlow。
这里有一个出现此“问题”的Q-learning CNN示例:https://github.com/tomrunia/DeepReinforcementLearning-Atari/blob/master/qnetwork.py
NVIDIA SMI显示低GPU利用率的示例:NVIDIA-SMI
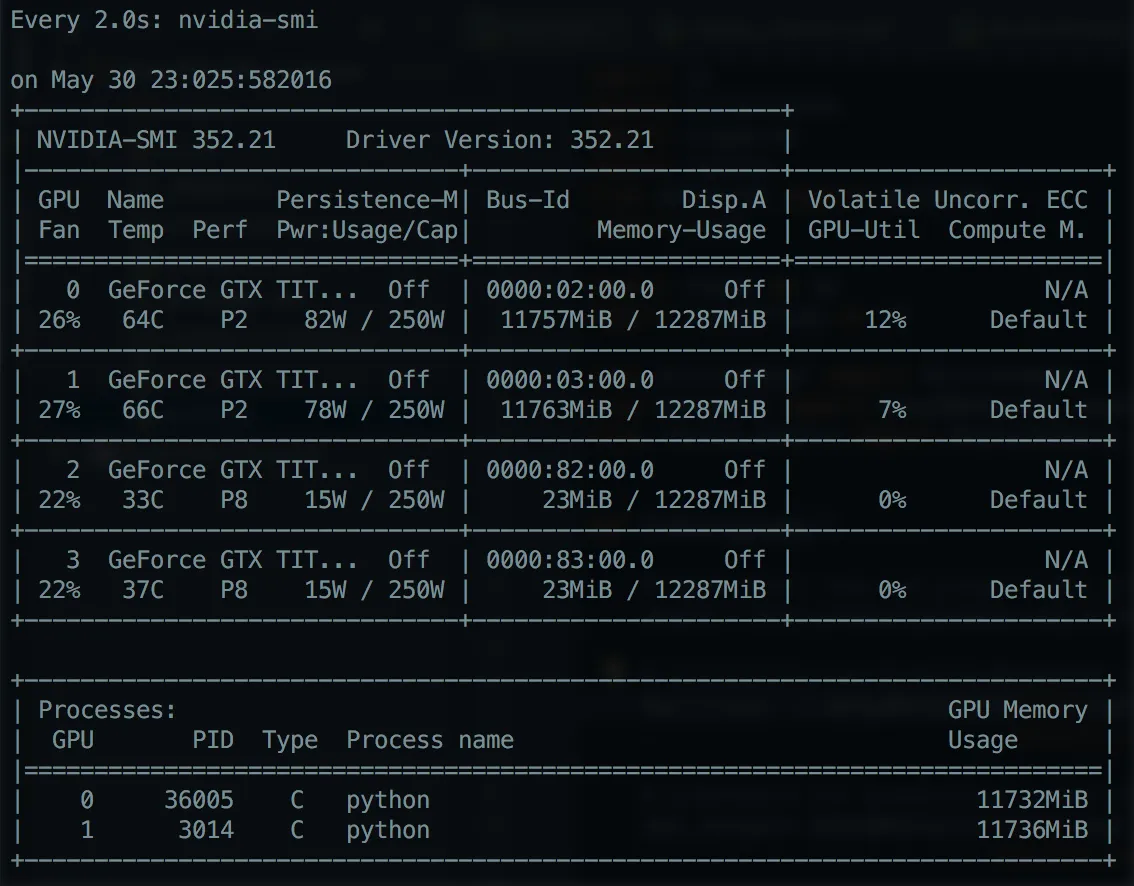{kind=link}
tf.float32的张量。结果在这里:http://pastebin.com/xrku9AjW正如您所看到的,GPU利用率似乎没有显着变化,甚至在增加批量大小时会降低。时间测量是100个批次的平均值,并使用time.time()记录。有什么线索错在哪里吗? - verified.human