我正在尝试训练一个简单的多层感知器,以完成Udacity深度学习课程的任务之一,即10类图像分类任务。更确切地说,任务是将来自各种字体的字母进行分类(数据集称为notMNIST)。
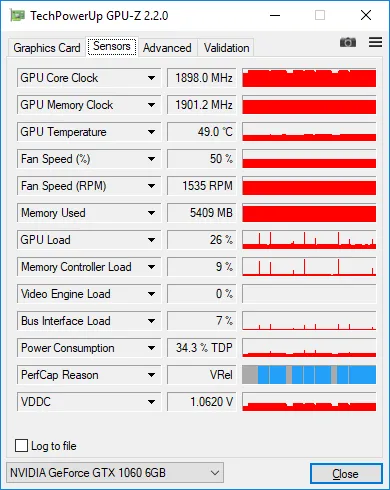
我编写的代码看起来相当简单,但无论如何,在训练过程中,GPU使用率始终非常低。我使用GPU-Z测量负载,显示只有25-30%。
这是我的当前代码:
graph = tf.Graph()
with graph.as_default():
tf.set_random_seed(52)
# dataset definition
dataset = Dataset.from_tensor_slices({'x': train_data, 'y': train_labels})
dataset = dataset.shuffle(buffer_size=20000)
dataset = dataset.batch(128)
iterator = dataset.make_initializable_iterator()
sample = iterator.get_next()
x = sample['x']
y = sample['y']
# actual computation graph
keep_prob = tf.placeholder(tf.float32)
is_training = tf.placeholder(tf.bool, name='is_training')
fc1 = dense_batch_relu_dropout(x, 1024, is_training, keep_prob, 'fc1')
fc2 = dense_batch_relu_dropout(fc1, 300, is_training, keep_prob, 'fc2')
fc3 = dense_batch_relu_dropout(fc2, 50, is_training, keep_prob, 'fc3')
logits = dense(fc3, NUM_CLASSES, 'logits')
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(
tf.cast(tf.equal(tf.argmax(y, 1), tf.argmax(logits, 1)), tf.float32),
)
accuracy_percent = 100 * accuracy
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
# ensures that we execute the update_ops before performing the train_op
# needed for batch normalization (apparently)
train_op = tf.train.AdamOptimizer(learning_rate=1e-3, epsilon=1e-3).minimize(loss)
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
step = 0
epoch = 0
while True:
sess.run(iterator.initializer, feed_dict={})
while True:
step += 1
try:
sess.run(train_op, feed_dict={keep_prob: 0.5, is_training: True})
except tf.errors.OutOfRangeError:
logger.info('End of epoch #%d', epoch)
break
# end of epoch
train_l, train_ac = sess.run(
[loss, accuracy_percent],
feed_dict={x: train_data, y: train_labels, keep_prob: 1, is_training: False},
)
test_l, test_ac = sess.run(
[loss, accuracy_percent],
feed_dict={x: test_data, y: test_labels, keep_prob: 1, is_training: False},
)
logger.info('Train loss: %f, train accuracy: %.2f%%', train_l, train_ac)
logger.info('Test loss: %f, test accuracy: %.2f%%', test_l, test_ac)
epoch += 1
到目前为止,我尝试了以下方法:
我将输入管道从简单的
feed_dict更改为tensorflow.contrib.data.Dataset。据我所知,它应该处理输入的效率,例如在单独的线程中加载数据。因此,与输入相关的瓶颈应该不存在。按照这里建议的方式收集了跟踪信息:https://github.com/tensorflow/tensorflow/issues/1824#issuecomment-225754659,但是这些跟踪信息并没有显示任何有趣的东西。 >90%的训练步骤都是矩阵乘法运算。
更改批次大小。当我将其从128更改为512时,负载从~30%增加到~38%,当我将其进一步增加到2048时,负载增加到~45%。我有6Gb GPU内存,并且数据集是单通道28x28图像。我真的应该使用如此大的批次大小吗?我应该进一步增加它吗?
总的来说,我应该担心低负载吗?这真的是我训练效率低的迹象吗?
这是带有128张图像的批次的GPU-Z截图。您可以看到低负载,当我在每个时代之后测量整个数据集的准确性时,偶尔会出现100%的峰值。