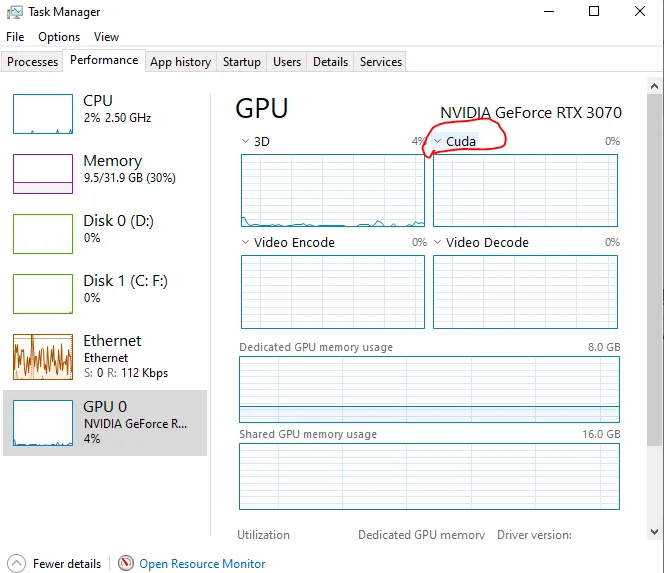
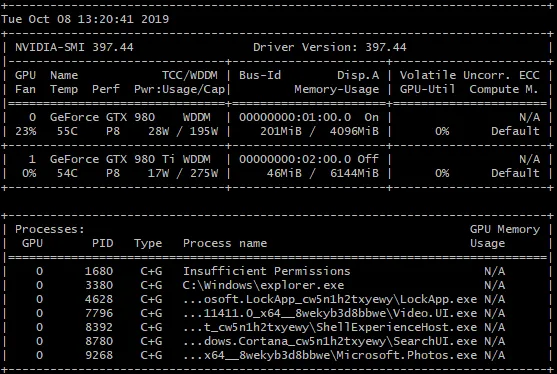
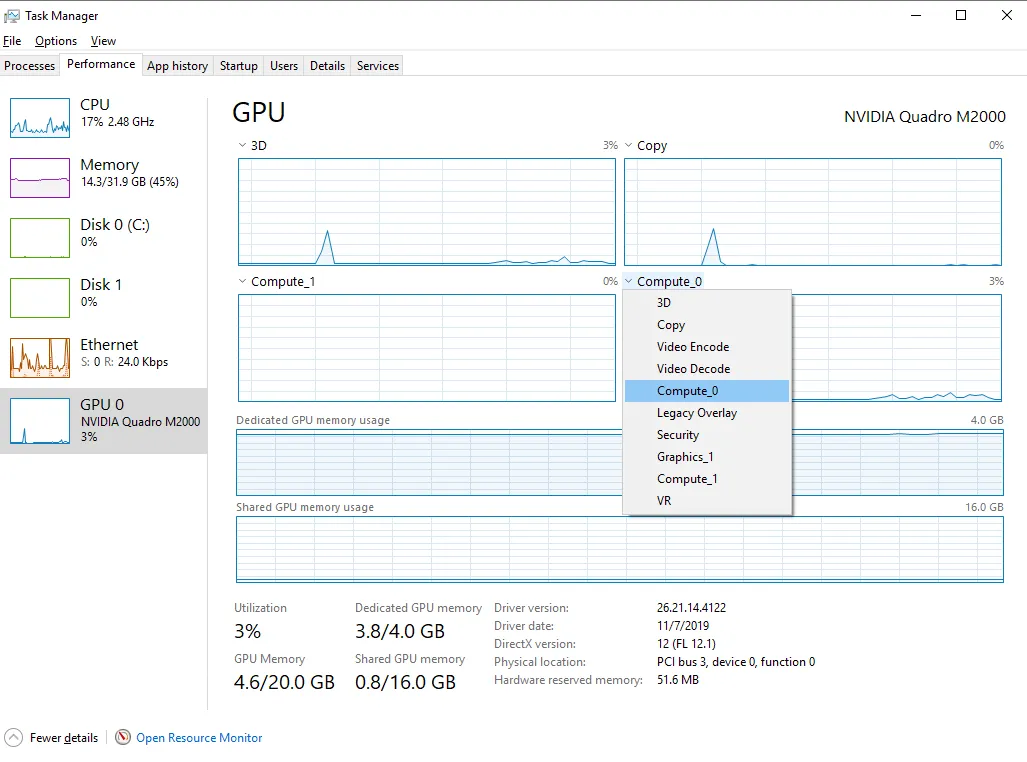
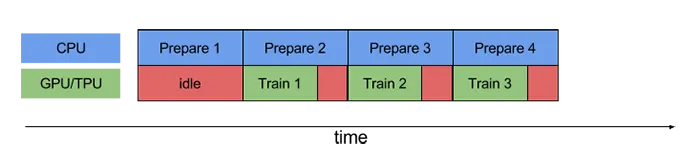
我正在使用 keras-gpu 和 tensorflow-gpu 运行一个卷积神经网络,使用的是 NVIDIA GeForce RTX 2080 Ti,在 Windows 10 上运行。我的电脑配备了 Intel Xeon e5-2683 v4 CPU(2.1 GHz)。我通过 Jupyter(最新的 Anaconda 发行版)运行代码。命令终端中的输出显示 GPU 正在被利用,但我运行的脚本需要比预期更长的时间来训练/测试数据,并且当我打开任务管理器时,GPU 利用率非常低。这里有一张图片: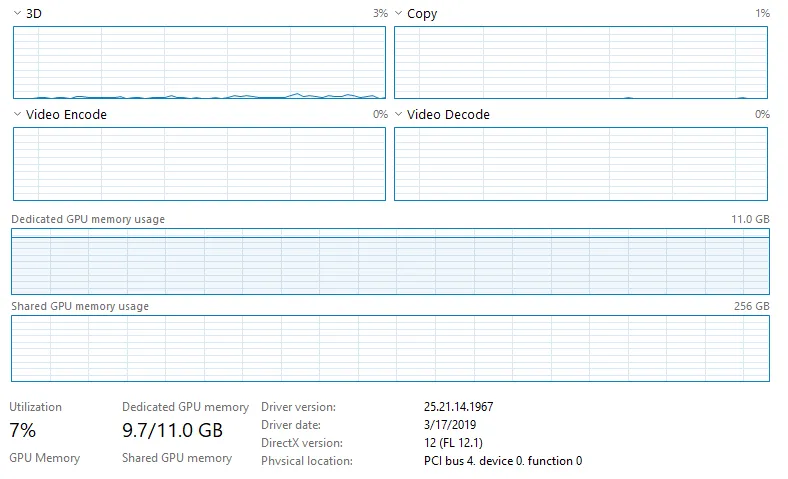
请注意,CPU 没有被利用,任务管理器中没有任何其他东西表明有任何东西被充分利用。我没有以太网连接,而是连接到 Wifi(不认为这会影响任何事情,但由于 Jupyter 是通过 Web 浏览器运行的,我不确定)。我正在对大量数据(~128GB)进行训练,这些数据都加载到 RAM 中(512GB)。我运行的模型是一个完全卷积神经网络(基本上是一个 U-Net 架构),具有 566,290 个可训练参数。我尝试过的事情包括: 1. 将批处理大小从 20 增加到 10,000(将 GPU 利用率从 ~3-4% 增加到 ~6-7%,训练时间大大缩短,与预期相符)。 2. 将 use_multiprocessing 设置为 True,并增加 model.fit 中的 worker 数量(没有效果)。我按照此网站上的安装步骤进行了操作:https://www.pugetsystems.com/labs/hpc/The-Best-Way-to-Install-TensorFlow-with-GPU-Support-on-Windows-10-Without-Installing-CUDA-1187/#look-at-the-job-run-with-tensorboard 请注意,这种安装方式不会安装CuDNN或CUDA。过去我曾尝试使用CUDA运行tensorflow-gpu(虽然已经两年多没用过,也许最新版本更容易),这就是我使用这种安装方法的原因。
这可能是GPU没有被充分利用的主要原因吗(没有CuDNN/CUDA)?这是否与专用GPU内存使用成为瓶颈有关?或者可能与我使用的网络结构(参数数量等)有关吗?
如果您需要更多有关我的系统或正在运行代码/数据的信息来帮助诊断,请告诉我。先感谢您!
编辑:我在任务管理器中注意到一些有趣的东西。批量大小为10,000的时代需要大约200秒的时间。在每个时代的最后约5秒钟内,GPU使用率增加到约15-17%(从每个时代的前195秒内的约6-7%增加)。不确定这是否有帮助或者除GPU之外是否存在瓶颈。
请注意,CPU 没有被利用,任务管理器中没有任何其他东西表明有任何东西被充分利用。我没有以太网连接,而是连接到 Wifi(不认为这会影响任何事情,但由于 Jupyter 是通过 Web 浏览器运行的,我不确定)。我正在对大量数据(~128GB)进行训练,这些数据都加载到 RAM 中(512GB)。我运行的模型是一个完全卷积神经网络(基本上是一个 U-Net 架构),具有 566,290 个可训练参数。我尝试过的事情包括: 1. 将批处理大小从 20 增加到 10,000(将 GPU 利用率从 ~3-4% 增加到 ~6-7%,训练时间大大缩短,与预期相符)。 2. 将 use_multiprocessing 设置为 True,并增加 model.fit 中的 worker 数量(没有效果)。我按照此网站上的安装步骤进行了操作:https://www.pugetsystems.com/labs/hpc/The-Best-Way-to-Install-TensorFlow-with-GPU-Support-on-Windows-10-Without-Installing-CUDA-1187/#look-at-the-job-run-with-tensorboard 请注意,这种安装方式不会安装CuDNN或CUDA。过去我曾尝试使用CUDA运行tensorflow-gpu(虽然已经两年多没用过,也许最新版本更容易),这就是我使用这种安装方法的原因。
这可能是GPU没有被充分利用的主要原因吗(没有CuDNN/CUDA)?这是否与专用GPU内存使用成为瓶颈有关?或者可能与我使用的网络结构(参数数量等)有关吗?
如果您需要更多有关我的系统或正在运行代码/数据的信息来帮助诊断,请告诉我。先感谢您!
编辑:我在任务管理器中注意到一些有趣的东西。批量大小为10,000的时代需要大约200秒的时间。在每个时代的最后约5秒钟内,GPU使用率增加到约15-17%(从每个时代的前195秒内的约6-7%增加)。不确定这是否有帮助或者除GPU之外是否存在瓶颈。