我有一个数据框,其中包含了几天的聚合数据。我想添加缺失的日期。
我参考了另一篇文章 Add missing dates to pandas dataframe,但不幸的是,它覆盖了我的结果(可能功能稍微有所改变)... 代码如下:
我参考了另一篇文章 Add missing dates to pandas dataframe,但不幸的是,它覆盖了我的结果(可能功能稍微有所改变)... 代码如下:
import random
import datetime as dt
import numpy as np
import pandas as pd
def generate_row(year, month, day):
while True:
date = dt.datetime(year=year, month=month, day=day)
data = np.random.random(size=4)
yield [date] + list(data)
# days I have data for
dates = [(2000, 1, 1), (2000, 1, 2), (2000, 2, 4)]
generators = [generate_row(*date) for date in dates]
# get 5 data points for each
data = [next(generator) for generator in generators for _ in range(5)]
df = pd.DataFrame(data, columns=['date'] + ['f'+str(i) for i in range(1,5)])
# df
groupby_day = df.groupby(pd.PeriodIndex(data=df.date, freq='D'))
results = groupby_day.sum()
idx = pd.date_range(min(df.date), max(df.date))
results.reindex(idx, fill_value=0)
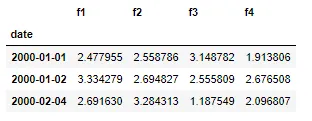
填补缺失日期索引前的结果
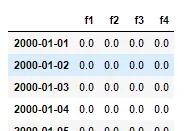
填补缺失日期索引后的结果
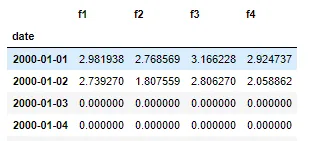
df.set_index(df.date, inplace=True)+df = df.resample('D').sum()这非常方便。 - Alter