以下是我的
我希望使用特定的向后填充条件,替换每一列中的
数据框的一部分,其中有许多缺失值。 A B
S a b c d e a b c d e
date
2020-10-15 1.0 2.0 NaN NaN NaN 10.0 11.0 NaN NaN NaN
2020-10-16 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2020-10-17 NaN NaN NaN 4.0 NaN NaN NaN NaN 13.0 NaN
2020-10-18 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2020-10-19 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2020-10-20 4.0 6.0 4.0 1.0 9.0 10.0 2.0 13.0 4.0 13.0
我希望使用特定的向后填充条件,替换每一列中的
NANs。例如,在(A,a)列中,缺失值出现在16号、17号、18号和19号这几天。下一个值是20日的'4'。我希望这个值(该列中下一个非缺失值)以逐步增加10%的比例分布在包括20日在内的所有日期上。也就是说,对于所有行中所有缺失值,都应采用这种方法填充它们。
我尝试使用bfill()函数,但无法理解如何将所需的公式作为选项纳入其中。
我已经查看了链接Pandas: filling missing values in time series forward using a formula和其他一些关于stackoverflow的链接。这与我的情况有些相似,但在我的情况下,给定列中NANs的数量性质是可变的,并跨越多行。相比较(A,a)列与(A,d)或(B,d)列。鉴于此,我发现很难采用该解决方案解决我的问题。
感谢任何帮助。
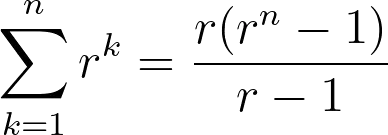 概括而言,我们需要3个量来计算每个单元格的值:
概括而言,我们需要3个量来计算每个单元格的值: