我有一个类似这样的熊猫数据表:
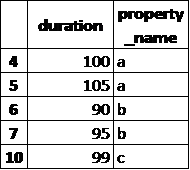
它有超过一吨的行数。我想要单独查看30或40个不同属性。
我希望为每个单独的属性创建一个基于持续时间的直方图,如属性A、属性B和属性C等。
我知道如何为所有属性创建它,就像下面我的代码所示:
df['duration'].plot(kind='hist', sharex=False, use_index=False, bins=100)
plt.show()
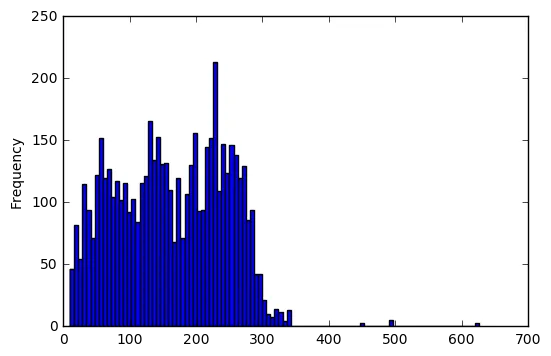
有什么想法可以解决这个问题吗?
我有一个类似这样的熊猫数据表:
它有超过一吨的行数。我想要单独查看30或40个不同属性。
我希望为每个单独的属性创建一个基于持续时间的直方图,如属性A、属性B和属性C等。
我知道如何为所有属性创建它,就像下面我的代码所示:
df['duration'].plot(kind='hist', sharex=False, use_index=False, bins=100)
plt.show()
有什么想法可以解决这个问题吗?
df:df = pd.DataFrame(dict(duration=np.random.rand(1000),
property_name=np.random.choice(list('abc'), 1000)))
df.groupby('property_name').hist(figsize=(10,2))
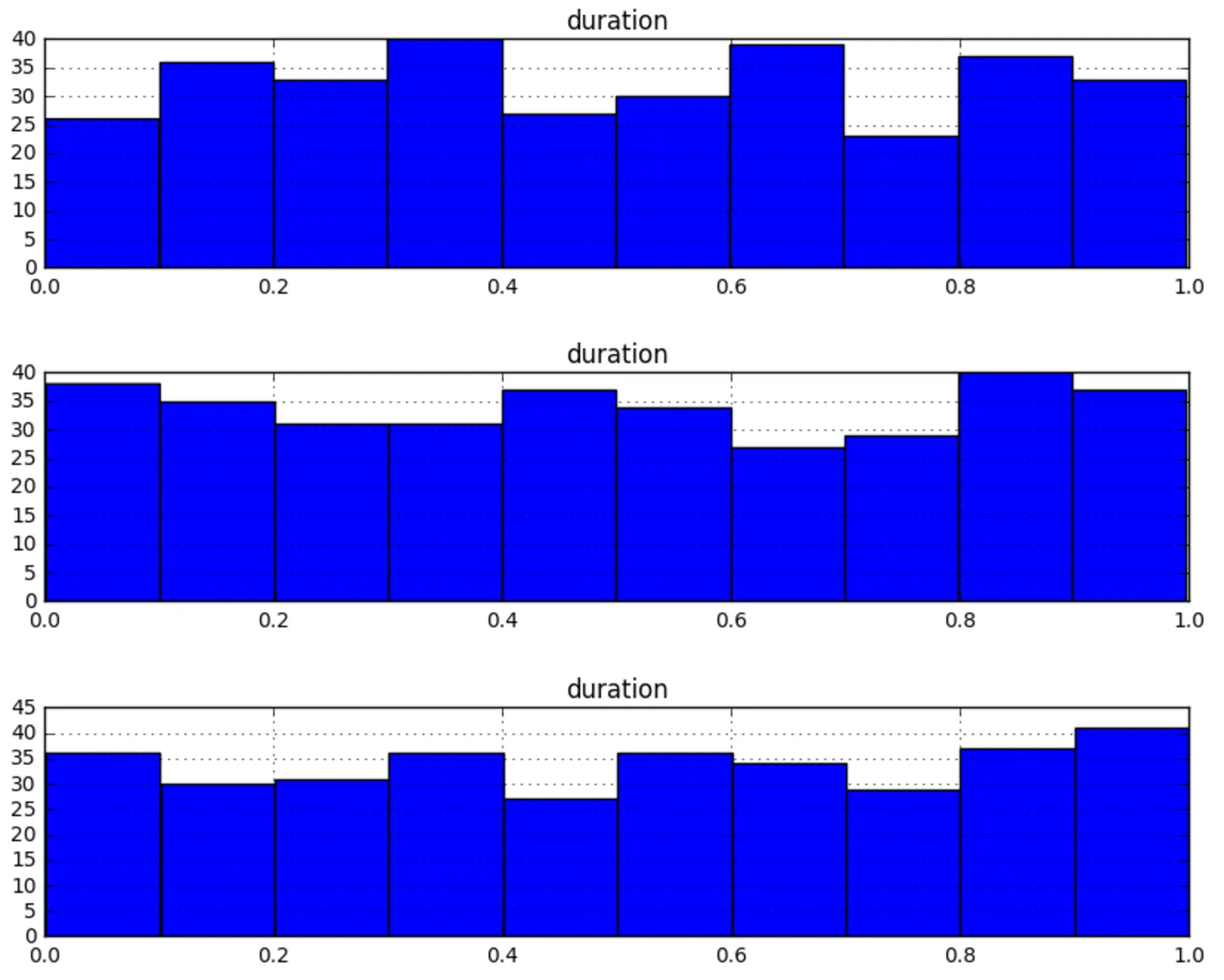
没关系,我明白了!
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.hist.html
df.groupby('property_name').hist(column='duration')
df.groupby('property_name').hist()。 - piRSquared