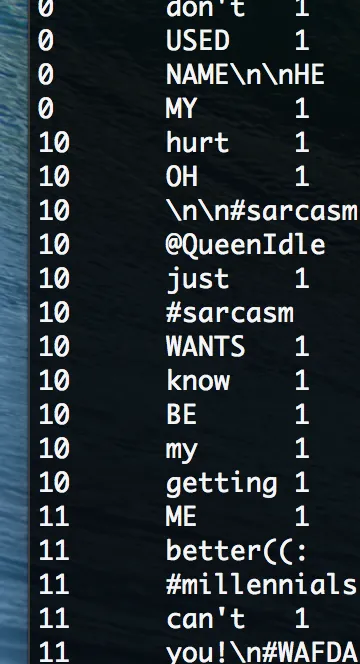
我已经运行了来自https://github.com/percyliang/brown-cluster的Brown聚类算法,以及Python实现的https://github.com/mheilman/tan-clustering。它们都会对每个独特的标记提供某种二进制和另一个整数。例如:
0 the 6
10 chased 3
110 dog 2
1110 mouse 2
1111 cat 2
二进制与整数是什么意思?
根据第一个链接,二进制被称为比特串(bit-string),参见http://saffron.deri.ie/acl_acl/document/ACL_ANTHOLOGY_ACL_P11-1053/
但我怎样从输出中判断dog and mouse and cat是一个聚类(cluster),而the and chased不在同一个聚类中呢?