我正在尝试在Python中实现
我看到了这个手动覆盖sklearn距离函数的优雅解决方案,并且我想使用相同的技术来覆盖代码的平均部分,但是我找不到它。
有人知道如何做吗? 距离度量不满足三角不等式有多重要? 如果有人知道使用余弦度量或满足距离和平均函数的不同有效实现,则也会非常有帮助。
非常感谢! 编辑: 在使用角距离而不是余弦距离之后,代码看起来像这样:
我注意到(通过数学计算)如果向量被标准化,标准平均值对于角度度量表现良好。据我所知,我需要在k_means_.py中更改
有人知道替代方案吗? 或者,有人知道如何使用一种总是强制质心标准化的函数来编辑此函数吗?
Kmeans算法,该算法将使用余弦距离作为距离度量,而不是欧几里德距离。
我知道使用不同的距离函数可能会导致灾难性后果,因此应该小心处理。使用余弦距离作为度量强制我更改平均函数(根据余弦距离的平均值必须是规范化向量的逐元素平均值)。我看到了这个手动覆盖sklearn距离函数的优雅解决方案,并且我想使用相同的技术来覆盖代码的平均部分,但是我找不到它。
有人知道如何做吗? 距离度量不满足三角不等式有多重要? 如果有人知道使用余弦度量或满足距离和平均函数的不同有效实现,则也会非常有帮助。
非常感谢! 编辑: 在使用角距离而不是余弦距离之后,代码看起来像这样:
def KMeans_cosine_fit(sparse_data, nclust = 10, njobs=-1, randomstate=None):
# Manually override euclidean
def euc_dist(X, Y = None, Y_norm_squared = None, squared = False):
#return pairwise_distances(X, Y, metric = 'cosine', n_jobs = 10)
return np.arccos(cosine_similarity(X, Y))/np.pi
k_means_.euclidean_distances = euc_dist
kmeans = k_means_.KMeans(n_clusters = nclust, n_jobs = njobs, random_state = randomstate)
_ = kmeans.fit(sparse_data)
return kmeans
我注意到(通过数学计算)如果向量被标准化,标准平均值对于角度度量表现良好。据我所知,我需要在k_means_.py中更改
_mini_batch_step()。但是这个函数相当复杂,我不知道该如何做。
有人知道替代方案吗? 或者,有人知道如何使用一种总是强制质心标准化的函数来编辑此函数吗?
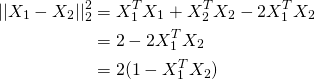
k_means_模块中的一个名为euclidean_distance的函数变量。如果您发布您的k-means代码以及要覆盖的函数,我可以给您更具体的答案。但是,如果您想自己完成,请在k_means_源代码中查找平均函数的名称并进行替换。 - charlesreid1k_means_.py中的平均函数是如何工作的,因此我无法理解如何更改它。 - ise372