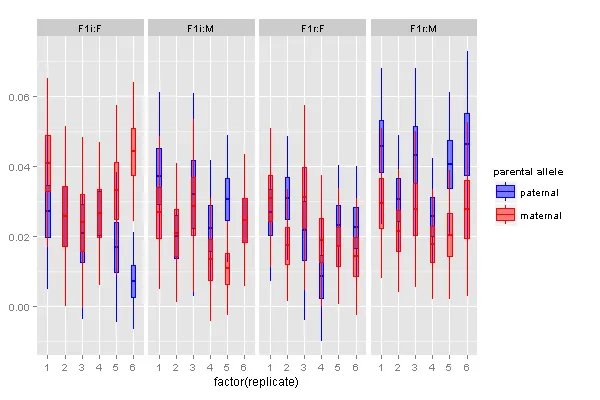
I have this data.frame:
my.df = data.frame(mean = c(0.045729661,0.030416531,0.043202944,0.025600973,0.040526913,0.046167044,0.029352414,0.021477789,0.027580529,0.017614864,0.020324659,0.027547972,0.0268722,0.030804717,0.021502093,0.008342398,0.02295506,0.022386184,0.030849534,0.017291356,0.030957321,0.01871551,0.016945678,0.014143042,0.026686185,0.020877973,0.028612298,0.013227244,0.010710895,0.024460647,0.03704981,0.019832982,0.031858501,0.022194059,0.030575241,0.024632496,0.040815748,0.025595652,0.023839083,0.026474704,0.033000706,0.044125751,0.02714219,0.025724641,0.020767752,0.026480009,0.016794441,0.00709195), std.dev = c(0.007455271,0.006120299,0.008243454,0.005552582,0.006871527,0.008920899,0.007137174,0.00582671,0.007439398,0.005265133,0.006180637,0.008312494,0.006628951,0.005956211,0.008532386,0.00613411,0.005741645,0.005876588,0.006640122,0.005339993,0.008842722,0.006246828,0.005532832,0.005594483,0.007268493,0.006634795,0.008287031,0.00588119,0.004479003,0.006333063,0.00803285,0.006226441,0.009681048,0.006457784,0.006045368,0.006293256,0.008062195,0.00857954,0.008160441,0.006830088,0.008095485,0.006665062,0.007437581,0.008599525,0.008242957,0.006379928,0.007168385,0.004643819), parent.origin = c("paternal","paternal","paternal","paternal","paternal","paternal","maternal","maternal","maternal","maternal","maternal","maternal","paternal","paternal","paternal","paternal","paternal","paternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","maternal","paternal","paternal","paternal","paternal","paternal","paternal","maternal","maternal","maternal","maternal","maternal","maternal","paternal","paternal","paternal","paternal","paternal","paternal"), group = c("F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:M","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1r:F","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:M","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F","F1i:F"), replicate = c(1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6,1,2,3,4,5,6))
我用以下代码生成了一个多方位的ggplot:
p1 = ggplot(data = my.df, aes(factor(replicate), color = factor(parent.origin)))
p1 = p1 + geom_boxplot(aes(fill = factor(parent.origin),lower = mean - std.dev, upper = mean + std.dev, middle = mean, ymin = mean - 3*std.dev, ymax = mean + 3*std.dev), position = position_dodge(width = 0), width = 0.5, alpha = 0.5, stat="identity") + facet_wrap(~group, ncol = 4)+scale_fill_manual(values = c("red","blue"),labels = c("maternal","paternal"),name = "parental allele")+scale_colour_manual(values = c("red","blue"),labels = c("maternal","paternal"),name = "parental allele")
这给出了这样的数字:
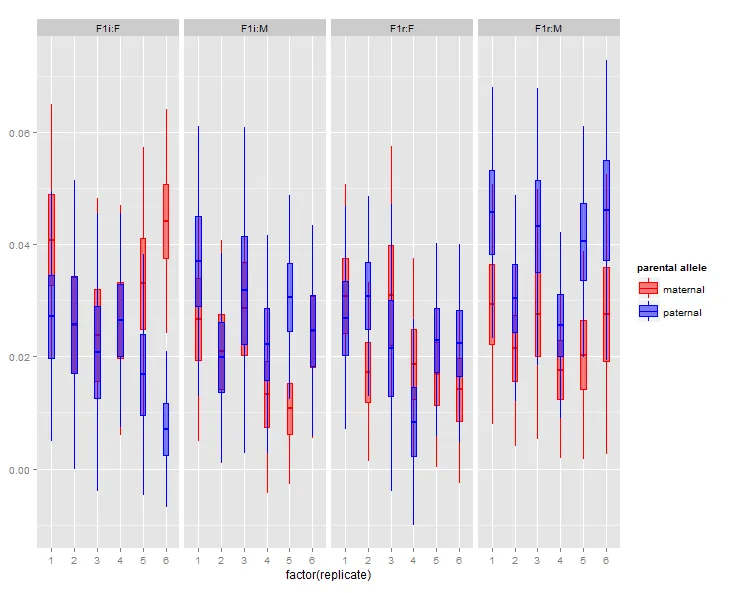 我只是想重新排列图例中的标签,以便“父系”在“母系”之上。
我只是想重新排列图例中的标签,以便“父系”在“母系”之上。