我在解释
考虑以下的MWE:
在上面的数组中,我不清楚如何使用这些值来确定聚类中心。我告诉K-Means给我2个聚类,但它却返回了8个值,但它们不能是所有4个特征的x、y坐标。
如果我绘制1.43706001,-0.29278015;这是有直觉意义的,它是一个位于预测聚类中心正中央的聚类。
cluster_centers_数组输出结果时遇到了困难。考虑以下的MWE:
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import numpy as np
# Load the data
iris = load_iris()
X, y = iris.data, iris.target
# shuffle the data
shuffle = np.random.permutation(np.arange(X.shape[0]))
X = X[shuffle]
# scale X
X = (X - X.mean()) / X.std()
# plot K-means centroids
km = KMeans(n_clusters = 2, n_init = 10) # establish the model
# fit the data
km.fit(X);
# km centers
km.cluster_centers_
array([[ 1.43706001, -0.29278015, 0.75703227, -0.89603057],
[ 0.78079175, -0.04797174, -0.96467783, -1.60799713]])
在上面的数组中,我不清楚如何使用这些值来确定聚类中心。我告诉K-Means给我2个聚类,但它却返回了8个值,但它们不能是所有4个特征的x、y坐标。
如果我绘制1.43706001,-0.29278015;这是有直觉意义的,它是一个位于预测聚类中心正中央的聚类。
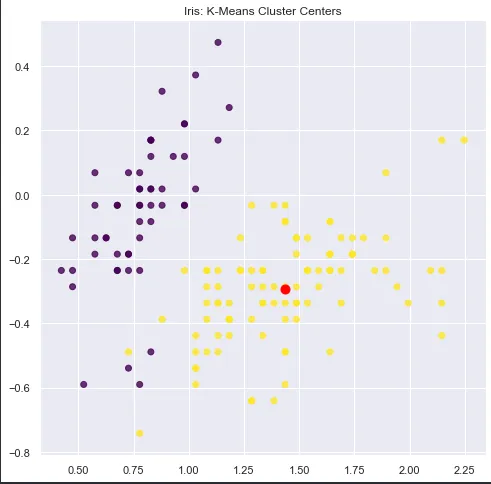
如果是这种情况,我的第二个聚类是0.78079175,-0.04797174,那么第2列和第3列的值是什么?