我需要向一个Pandas数据框中添加2列,这两列包含有条件的平均值和标准差。
在这个示例中,我需要添加两列:
我查看了
我知道如何将.mean或.std应用于整个pandas系列,而不需要条件:
我还发现,使用分组和转换操作可以做一些类似的事情,但没有函数能够动态检查每一行。
感谢你的帮助。
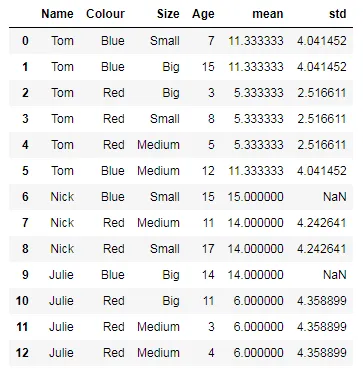
这是我期望的输出结果。感谢解答: 输出数据帧
# Import pandas library
import pandas as pd
# Initialize list of lists
data = [
['Tom', 'Blue', 'Small', 10, ],
['Tom', 'Blue', 'Big', 15, ],
['Tom', 'Red', 'Big', 3, ],
['Tom', 'Red', 'Small', 8, ],
['Tom', 'Red', 'Medium', 5, ],
['Tom', 'Blue', 'Medium', 12, ],
['Nick', 'Blue', 'Small', 15, ],
['Nick', 'Red', 'Medium', 11, ],
['Nick', 'Red', 'Small', 17, ],
['Julie', 'Blue', 'Big', 14, ],
['Julie', 'Red', 'Big', 11, ],
['Julie', 'Red', 'Medium', 3, ],
['Julie', 'Red', 'Medium', 4, ],
]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns = ['Name', 'Colour', 'Size', 'Age'])
# print dataframe.
df
在这个示例中,我需要添加两列:
df['mean'] 和 df['std'],仅限于名称和颜色的条件。我查看了
.mean() 和 .std()文档,但没有找到添加一组条件的方法。我认为我可能需要两个函数,对于每一行,将名称和颜色作为参数,计算整个系列的平均值或标准差,然后填充新的列。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.std.html
我认为我需要一个函数,动态检查每一行的名称和颜色,因为我的应用程序是针对有数千个名称和数千种颜色的数据框架,不像这个示例数据框架。我知道如何将.mean或.std应用于整个pandas系列,而不需要条件:
df['Age'].std()
或者
df['Age'].mean()
我还发现,使用分组和转换操作可以做一些类似的事情,但没有函数能够动态检查每一行。
df['mean'] = df.groupby(['Name','Colour']).transform('mean')
感谢你的帮助。
这是我期望的输出结果。感谢解答: 输出数据帧
{kind=link}
df.groupby(['Name', 'Colour']).transform('mean')有什么问题? - Danstd的transform应该可以工作。你能否评论一下为什么不行?我猜测你会得到ValueError: Wrong number of items passed 2, placement implies 1是因为你需要仅转换 Age 列。在添加了mean列之后,它也会进行转换。 - ALollz