我已经使用R包nlme和其中的gnls()函数构建了几个广义非线性最小二乘模型(指数衰减)。我之所以不仅使用基本的nls()函数构建非线性最小二乘模型,是因为我想能够对异方差进行建模以避免转换。我的模型大致如下:
与简单的
现在我想在
这部分无法使用
由于这似乎不适用于
我的当前最佳解决方案是使用
model <- gnls(Response ~ C * exp(k * Explanatory1) + A,
start = list(C = c(C1,C1), k = c(k1,k1), A = c(A1,A1)),
params = list(C ~ Explanatory2, k ~ Explanatory2,
A ~ Explanatory2),
weights = varPower(),
data = Data)
与简单的
nls() 模型相比,关键区别在于 weights 参数,它通过解释变量使异方差建模成为可能。与 gnls() 的线性等效物是广义最小二乘法,使用 nlme 的 gls() 函数运行。现在我想在
R 中计算置信区间,并将其与我的模型拟合一起绘制在 ggplot()(ggplot2 包)中。对于 gls() 对象,我会这样做:NewData <- data.frame(Explanatory1 = c(...), Explanatory2 = c(...))
NewData$fit <- predict(model, newdata = NewData)
到目前为止,一切都很顺利,我得到了我的模型适配。
modmat <- model.matrix(formula(model)[-2], NewData)
int <- diag(modmat %*% vcov(model) %*% t(modmat))
NewData$lo <- with(NewData, fit - 1.96*sqrt(int))
NewData$hi <- with(NewData, fit + 1.96*sqrt(int))
这部分无法使用
gnls()工作,因此我无法获得上限和下限的模型预测。由于这似乎不适用于
gnls()对象,我已经查阅了教科书以及之前提出的问题,但没有一个符合我的需求。我找到的唯一类似的问题是如何在r中计算非线性最小二乘的置信区间?。在顶部答案中,建议使用investr::predFit()或使用drc::drm()构建模型,然后使用常规的predict()函数。但这些解决方案都不能帮助我处理gnls()。我的当前最佳解决方案是使用
confint()函数计算三个参数(C、k、A)的95%置信区间,然后编写两个分别使用Cmin、kmin和Amin以及Cmax、kmax和Amax的上限和下限置信度的函数。然后我使用这些函数来预测值,然后使用ggplot()绘制图形。但是,我对结果并不完全满意,也不确定这种方法是否最优。
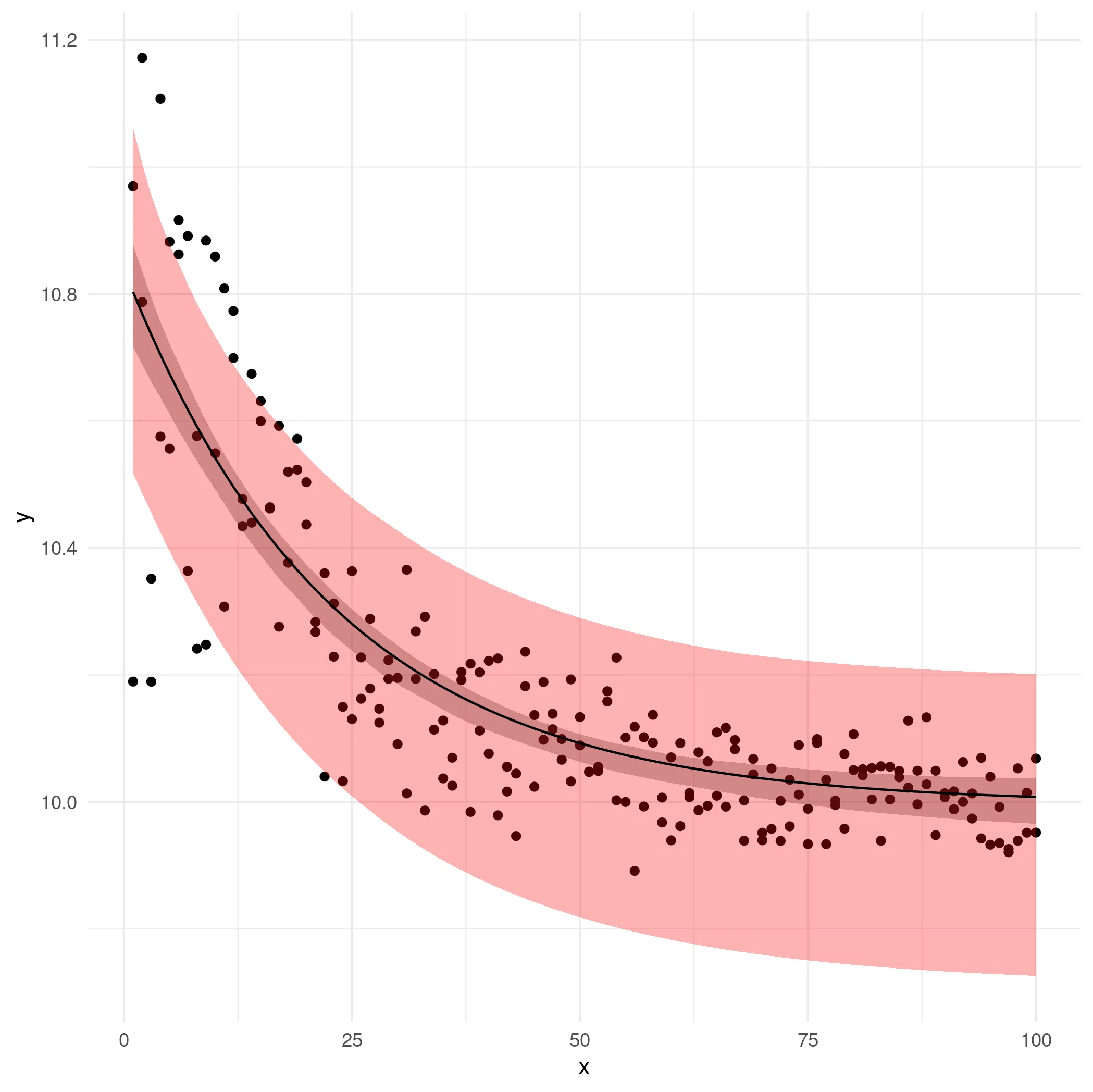
以下是一个最小可重现示例,为简单起见忽略了第二个分类解释变量:
# generate data
set.seed(10)
x <- rep(1:100,2)
r <- rnorm(x, mean = 10, sd = sqrt(x^-1.3))
y <- exp(-0.05*x) + r
df <- data.frame(x = x, y = y)
# find starting values
m <- nls(y ~ SSasymp(x, A, C, logk))
summary(m) # A = 9.98071, C = 10.85413, logk = -3.14108
plot(m) # clear heteroskedasticity
# fit generalised nonlinear least squares
require(nlme)
mgnls <- gnls(y ~ C * exp(k * x) + A,
start = list(C = 10.85413, k = -exp(-3.14108), A = 9.98071),
weights = varExp(),
data = df)
plot(mgnls) # more homogenous
# plot predicted values
df$fit <- predict(mgnls)
require(ggplot2)
ggplot(df) +
geom_point(aes(x, y)) +
geom_line(aes(x, fit)) +
theme_minimal()
编辑以下Ben Bolker的答案
标准的非参数自助法解决方案应用于第二个模拟数据集,该数据集更接近我的原始数据,并包括第二个分类解释变量:
# generate data
set.seed(2)
x <- rep(sample(1:100, 9), 12)
set.seed(15)
r <- rnorm(x, mean = 0, sd = 200*x^-0.8)
y <- c(200, 300) * exp(c(-0.08, -0.05)*x) + c(120, 100) + r
df <- data.frame(x = x, y = y,
group = rep(letters[1:2], length.out = length(x)))
# find starting values
m <- nls(y ~ SSasymp(x, A, C, logk))
summary(m) # A = 108.9860, C = 356.6851, k = -2.9356
plot(m) # clear heteroskedasticity
# fit generalised nonlinear least squares
require(nlme)
mgnls <- gnls(y ~ C * exp(k * x) + A,
start = list(C = c(356.6851,356.6851),
k = c(-exp(-2.9356),-exp(-2.9356)),
A = c(108.9860,108.9860)),
params = list(C ~ group, k ~ group, A ~ group),
weights = varExp(),
data = df)
plot(mgnls) # more homogenous
# calculate predicted values
new <- data.frame(x = c(1:100, 1:100),
group = rep(letters[1:2], each = 100))
new$fit <- predict(mgnls, newdata = new)
# calculate bootstrap confidence intervals
bootfun <- function(newdata) {
start <- coef(mgnls)
dfboot <- df[sample(nrow(df), size = nrow(df), replace = TRUE),]
bootfit <- try(update(mgnls,
start = start,
data = dfboot),
silent = TRUE)
if(inherits(bootfit, "try-error")) return(rep(NA, nrow(newdata)))
predict(bootfit, newdata)
}
set.seed(10)
bmat <- replicate(500, bootfun(new))
new$lwr <- apply(bmat, 1, quantile, 0.025, na.rm = TRUE)
new$upr <- apply(bmat, 1, quantile, 0.975, na.rm = TRUE)
# plot data and predictions
require(ggplot2)
ggplot() +
geom_point(data = df, aes(x, y, colour = group)) +
geom_ribbon(data = new, aes(x = x, ymin = lwr, ymax = upr, fill = group),
alpha = 0.3) +
geom_line(data = new, aes(x, fit, colour = group)) +
theme_minimal()
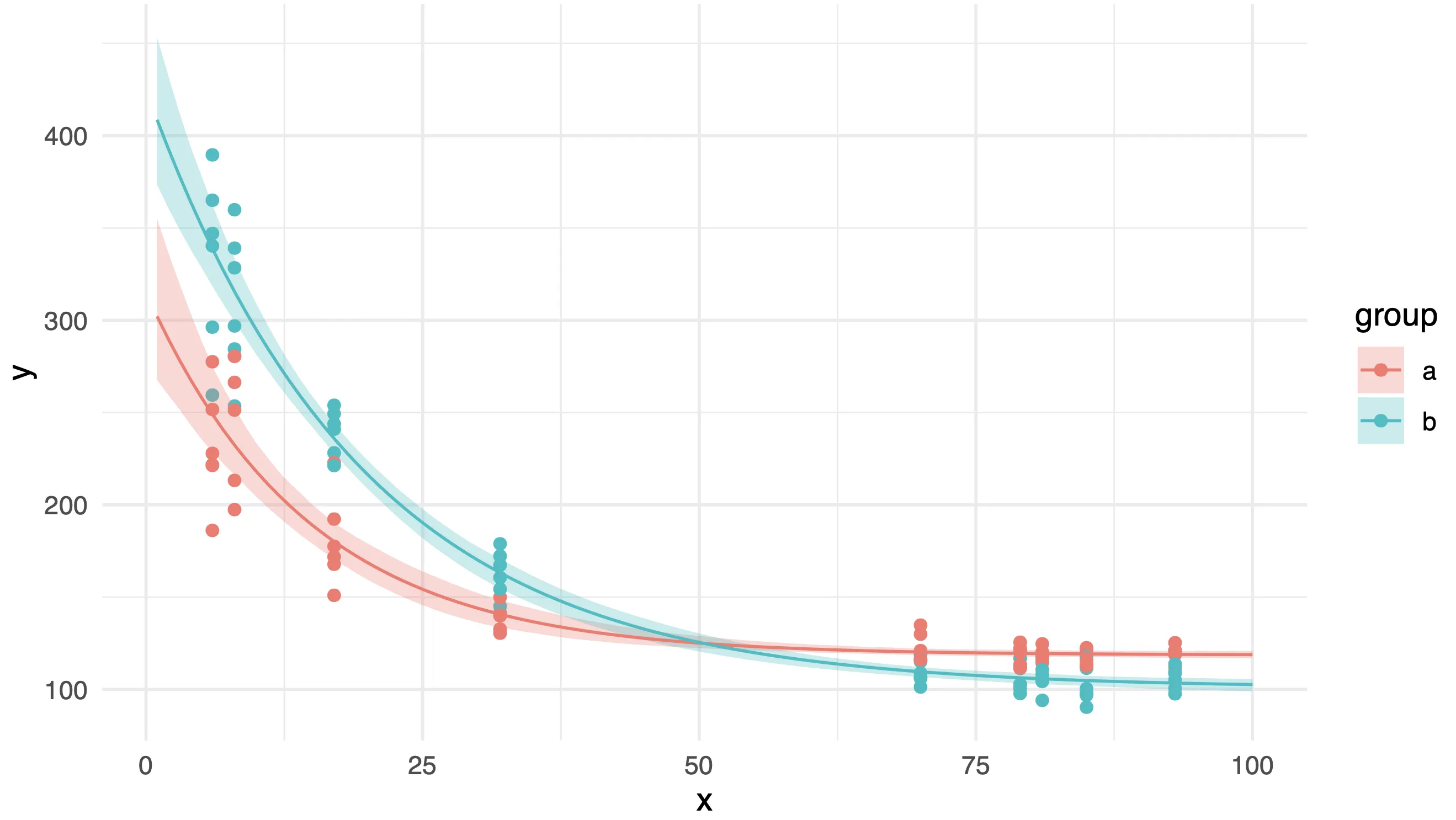
这是生成的图表,看起来很整洁!