线性回归和逻辑回归有什么区别?
1
线性回归输出作为概率
使用线性回归输出作为概率是一种错误的做法,因为输出可能为负数并且大于1,而概率不可能。由于回归可能会产生小于0或大于1的概率,因此引入了逻辑回归。
来源: http://gerardnico.com/wiki/data_mining/simple_logistic_regression
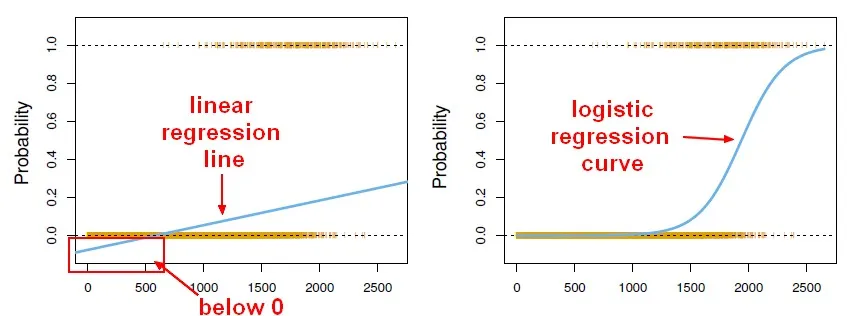
结果
在线性回归中,结果(因变量)是连续的,它可以有无限数量的可能值。
在逻辑回归中,结果(因变量)只有有限数量的可能值。
因变量
当响应变量具有分类属性时,使用逻辑回归。例如,是/否,真/假,红/绿/蓝,第1/2/3/4等。
当响应变量是连续的时,使用线性回归。例如,重量,身高,小时数等。
方程
线性回归给出一个方程,其形式为Y = mX + C,即一次方程。
然而,逻辑回归给出的方程的形式为Y = eX + e-X
系数解释
在线性回归中,独立变量的系数解释非常直接(即保持所有其他变量不变,该变量增加一个单位时,预期的因变量将增加/减少 xxx)。
然而,在逻辑回归中,根据您使用的家族(二项式,Poisson等)和链接(对数,logit,反对数等),解释是不同的。
误差最小化技术
线性回归使用普通最小二乘法来最小化误差并得到最佳拟合,而逻辑回归使用极大似然法来得到解决方案。
通常通过最小化模型对数据的最小二乘误差来解决线性回归问题,因此大误差会被平方惩罚。
逻辑回归完全相反。使用逻辑损失函数会导致大误差被渐近地惩罚成常数。
考虑对分类{0,1}结果进行线性回归,以了解为什么这是一个问题。如果您的模型预测结果为38,而真相为1,则您不会有损失。线性回归会试图减少那38,逻辑回归则不会那么多2。
7
在线性回归中,输出(因变量)是连续的。它可以有无限多种可能的值。在逻辑回归中,输出(因变量)只有有限数量的可能值。
例如,如果X包含房屋面积的平方英尺,Y包含这些房屋相应的销售价格,您可以使用线性回归来预测售价作为房屋大小的函数。虽然可能的售价实际上不可能是任何一个,但是由于有太多可能的值,所以会选择线性回归模型。
如果您想要根据房屋大小预测是否会以超过200,000美元的价格出售,则应使用逻辑回归。可能的输出要么是Yes(房子将以超过200,000美元的价格出售),要么是No(房子不会出售)。
3
在之前的答案中添加一些内容。
线性回归
旨在解决预测/估计给定元素X(例如f(x))输出值的问题。预测的结果是一个连续的函数,其中值可能为正或负。在这种情况下,通常有一个包含大量示例的输入数据集以及每个示例的输出值。目标是能够将模型拟合到此数据集,以便能够预测新不同/从未见过的元素的输出。以下是将一条直线拟合到一组点的经典示例,但通常可以使用线性回归来拟合更复杂的模型(使用更高的多项式次数):
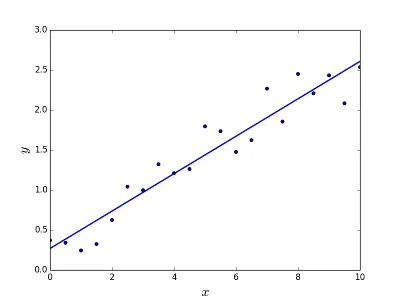
解决问题
线性回归可以通过两种不同的方式解决:
- 正规方程(直接解决问题的方法)
- 梯度下降(迭代方法)
逻辑回归
旨在解决给定元素必须分类为N个类别的分类问题。典型的例子是,例如,给定一封邮件以将其分类为垃圾邮件或非垃圾邮件,或者给定一个车辆以找出它属于哪个类别(汽车、卡车、货车等)。基本上输出是有限的一组离散值。
解决问题
只能使用梯度下降解决逻辑回归问题。总体上,其公式非常类似于线性回归,唯一的区别在于使用不同的假设函数。在线性回归中,假设具有以下形式:
h(x) = theta_0 + theta_1*x_1 + theta_2*x_2 ..
这里的theta是我们试图拟合的模型,而[1,x_1,x_2,..]是输入向量。在逻辑回归中,假设函数不同:
g(x) = 1 / (1 + e^-x)
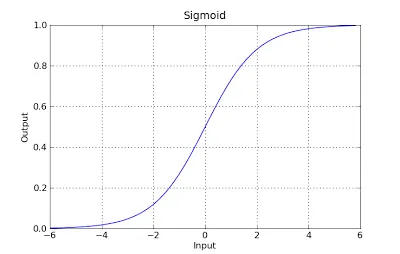
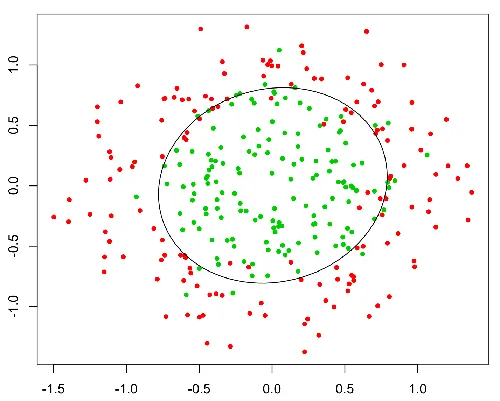
这个函数有一个很好的特性,基本上它会将任何值映射到[0,1]范围内,这对于处理分类过程中的概率是合适的。例如,在二元分类的情况下,g(X)可以被解释为属于正类的概率。在这种情况下,通常有不同的类别,它们是用一个决策边界分隔的,这基本上是一个曲线,决定了不同类别之间的分离。下面是一个数据集被分为两个类别的示例。
您还可以使用以下代码生成线性回归曲线 q_df = details_df # q_df = pd.get_dummies(q_df)
q_df = pd.get_dummies(q_df, columns=[
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
])
q_1_df = q_df["1"]
q_df = q_df.drop(["2", "3", "4", "5"], axis=1)
(import statsmodels.api as sm)
x = sm.add_constant(q_df)
train_x, test_x, train_y, test_y = sklearn.model_selection.train_test_split(
x, q3_rechange_delay_df, test_size=0.2, random_state=123 )
lmod = sm.OLS(train_y, train_x).fit() lmod.summary()
lmod.predict()[:10]
lmod.get_prediction().summary_frame()[:10]
sm.qqplot(lmod.resid,line="q") plt.title("Q-Q plot of Standardized Residuals") plt.show()
这段代码使用了Python的statsmodels库,创建并拟合了一个普通最小二乘回归模型(lmod),并显示了该模型的统计摘要信息。然后在前十个观测值上使用预测函数进行预测,并且通过get_prediction()方法获取置信区间和预测区间的信息。最后,使用sm.qqplot()方法绘制了标准化残差的Q-Q图。
因此,如果要预测您是否患有癌症Y/N(或概率)-请使用逻辑回归。如果想知道您还能活多少年-请使用线性回归!
基本区别:
线性回归是一种回归模型,其输出是非离散/连续的函数值。因此这种方法会给出一个数值结果。例如:给定x,f(x)是多少。
例如,给定一个不同因素和物业价格的训练集,在训练后我们可以提供所需的因素以确定物业价格。
逻辑回归基本上是一种二元分类算法,这意味着该函数将生成离散输出。例如:对于给定的x,如果f(x)>threshold,则将其分类为1,否则将其分类为0。
例如,给定一组脑肿瘤大小作为训练数据,我们可以使用大小作为输入来确定它是良性肿瘤还是恶性肿瘤。因此,这里的输出要么是0,要么是1。
*这里的函数基本上是假设函数。
简单来说,线性回归是一种回归算法,可输出可能的连续和无限值;逻辑回归被认为是一种二元分类器算法,输出输入属于标签(0或1)的“概率”。
1
回归意味着连续变量,线性意味着y和x之间存在线性关系。
例如:您正在尝试从经验年数预测薪水。因此,薪水是自变量(y),经验年数是因变量(x)。
y=b0+ b1*x1
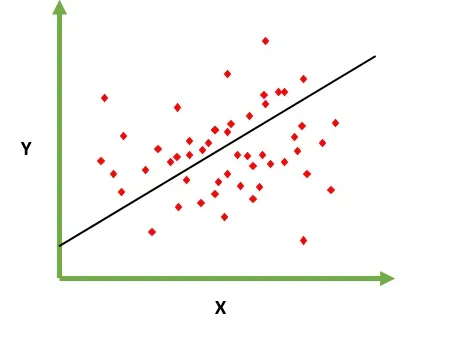 我们正在寻找常数b0和b1的最佳值,以给出您观察数据的最佳拟合线。
这是一条直线方程,它从x=0到非常大的值给出连续值。
这条线称为线性回归模型。
我们正在寻找常数b0和b1的最佳值,以给出您观察数据的最佳拟合线。
这是一条直线方程,它从x=0到非常大的值给出连续值。
这条线称为线性回归模型。
逻辑回归是分类技术的一种类型。不要被回归这个词所误导。在这里,我们预测y是否等于0或1。
在这里,我们首先需要从下面的公式中找到给定x时y=1的概率p(y=1)。
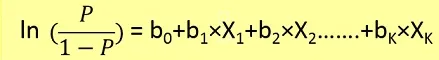
概率 p 与 y 相关,公式如下

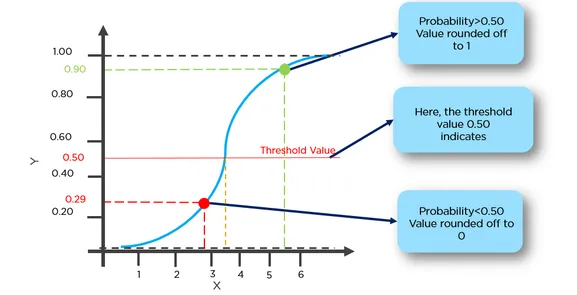 在这里,红点将被预测为0,而绿点将被预测为1。
在这里,红点将被预测为0,而绿点将被预测为1。在线性回归中,残差被假定为正态分布。 在逻辑回归中,残差需要是独立的,但不需要是正态分布的。
线性回归假设解释变量的值的恒定变化导致响应变量的恒定变化。 如果响应变量的值表示概率(在逻辑回归中),则这种假设不成立。
广义线性模型(GLM)不假设因变量和自变量之间存在线性关系。然而,在logit模型中,它假设链接函数和自变量之间存在线性关系。
例如:在一个场景中,给定X的值是平方英尺的地块大小,然后预测Y即地块价格属于线性回归。
如果您想根据大小预测地块是否会以超过300000卢比的价格出售,则应使用逻辑回归。可能的输出要么是“是”,即地块将以超过300000卢比的价格出售,要么是“否”。
逻辑回归用于预测类别输出,例如是/否,低/中/高等。基本上有两种类型的逻辑回归:二元逻辑回归(是/否,批准/不批准)或多类逻辑回归(低/中/高,数字0-9等)
另一方面,线性回归是当您的因变量(y)是连续的时使用。 y = mx + c 是一个简单的线性回归方程(m = 斜率,c是y截距)。多元线性回归具有多个自变量(x1,x2,x3等)
原文链接
- 相关问题
- 4 MATLAB:线性回归
- 3 线性回归模型
- 3 线性回归代码
- 3 多元线性回归
- 8 为什么逻辑回归被称为回归?
- 9 D3.js 线性回归
- 16 3D线性回归
- 10 比较贝叶斯线性回归和普通线性回归
- 27 逻辑回归和softmax回归的区别
- 3 聚合线性回归